<Data Engineering with AWS> 6장을 실습한 내용입니다.
이번 글에서는 이론 요약이 아닌 실습 파트를 따라 해 보려고 합니다! 8장 실습을 진행하려고 했는데 이를 위해서는 앞 장과 이어지기 때문에 6장부터의 실습부터 블로깅합니다.
지난 6장에서는 <배치 및 스트리밍 데이터 수집>을 학습했습니다. 따라서 이 장에서는 AWS DMS를 사용하여 데이터베이스에서 데이터를 수집한 다음, Amazon Kinesis를 사용하여 스트리밍 데이터를 수집하는 방법을 실습합니다. 단계별로 차근차근 해 봅시다!
1. AWS DMS로 데이터 수집
① 새 MySQL 데이터베이스 인스턴스 생성
첫 번째 단계에서는 프리 티어 적격 데이터베이스 인스턴스에 대한 기본 간편 생성 설정을 사용하여 새 MySQL 데이터베이스를 생성합니다.
- AWS Management Console(https://console.aws.amazon.com)에 로그인합니다.
- 상단 검색 표시줄에서 RDS를 검색하고 선택하여 RDS 콘솔에 액세스합니다.
- 왼쪽 메뉴에서 데이터베이스를 클릭합니다.
- 데이터베이스 생성을 클릭합니다.
- 데이터베이스 생성 방법으로 손쉬운 생성을 선택합니다.
- 엔진 유형에서 MySQL을 선택합니다.
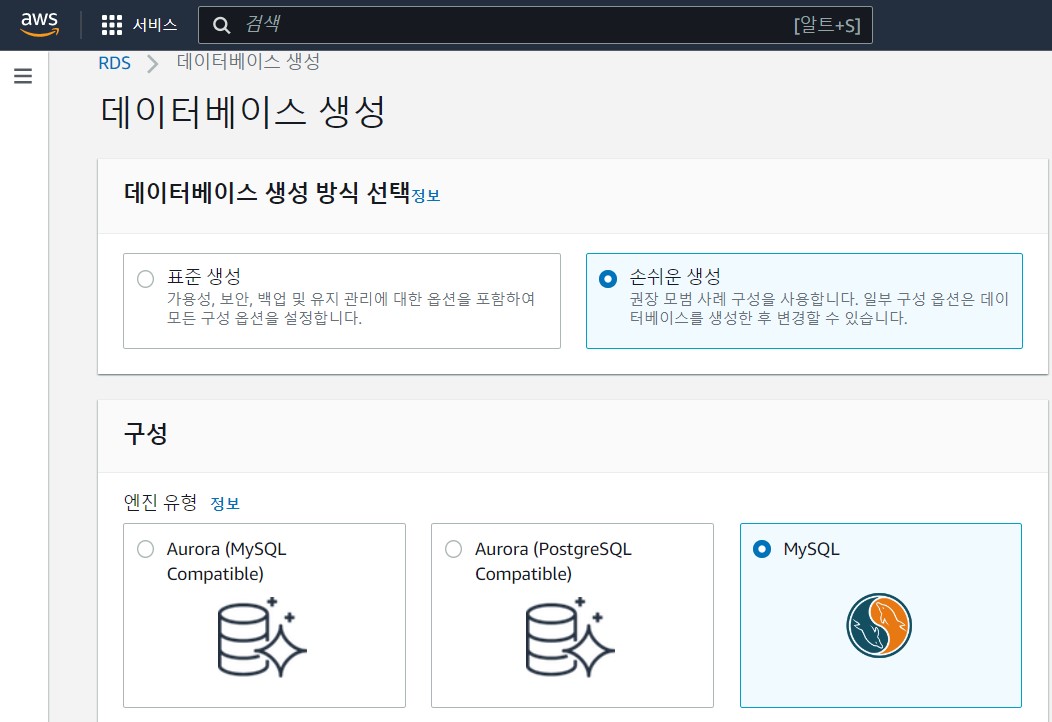
7. DB 인스턴스 크기에서 프리 티어(db.t2.micro)를 선택합니다.
8. DB 인스턴스 식별자에 dataeng-mysql-1을 입력합니다.
9. 마스터 암호에 비밀번호를 입력하고, 이 비밀번호는 나중에 필요하므로 비밀번호를 메모해 둡니다.
10. 데이터베이스 만들기를 클릭합니다.

11. 방금 만든 데이터베이스를 클릭하고 연결&보안 아래의 엔드포인트 속성(데이터베이스 인스턴스의 호스트 이름)을 기록해 둡니다.
12. 엔드포인트 URL이 표시되기 전에 데이터베이스가 생성되는 데에는 몇 분 정도 걸릴 수 있습니다.

이렇게 새로운 MySQL 데이터베이스 인스턴스가 생성되었습니다!
② Amazon EC2 인스턴스를 사용하여 데모 데이터 로드
이번엔 일부 데모 데이터를 데이터베이스에 로드하기 위해 Amazon EC2 인스턴스를 생성해 보겠습니다.
- AWS Management Console에서 상단 검색 표시줄을 사용하여 EC2를 검색하고 선택합니다.
- 왼쪽 메뉴에서 인스턴스를 클릭합니다.
- 오른쪽 상단에서 인스턴스 시작을 클릭합니다.
- Amazon Linux 2 AMI(HVM), SSD Volume Type을 선택합니다.
- 인스턴스 유형에서 t2.micro를 선택한 후 인스턴스 세부 정보 구성을 선택합니다.

6. 인스턴스 세부 구성에서 Auto-assign Public IP가 Enable로 설정되어 있는지 확인합니다.
7. 페이지를 쭉 내리면 사용자 데이터 섹션이 있습니다. 아래 bash 스크립트를 이 섹션에 붙여넣습니다. 스크립트는 인스턴스가 처음 시작될 때 실행됩니다. 이때, <PASSWORD>를 ①의 9단계에서 설정한 비밀번호로 바꾸고 <HOST>를 ①의 11단계에서 기록한 MySQL 데이터베이스 인스턴스 엔드포인트의 이름으로 바꿉니다.
#!/bin/bash
yum install -y mariadb
curl https://downloads.mysql.com/docs/sakila-db.zip -o sakila.zip
unzip sakila.zip
cd sakila-db
mysql --host=<HOST> --user=admin --password=<PASSWORD> -f < sakila-schema.sql
mysql --host=<HOST> --user=admin --password=<PASSWORD> -f < sakila-data.sql
8. 스토리지추가를 클릭 하고 모든 기본 설정을 그대로 둡니다.
9. 이름 및 태그에서 태그 추가를 클릭합니다. 키를 이름으로, 값을 dataeng-book-ec2로 설정합니다.
10. 네트워크 설정에서 보안 그룹 구성을 클릭하고 보안 그룹 할당에서 기존 보안 그룹 선택을 선택합니다.
11. default라는 보안 그룹을 선택합니다.
12. 키 페어(로그인)에서 새 키 페어 생성을 선택 하고 새 키 쌍의 이름(예: dataeng-book-key)을 작성합니다. 그러면 키 페어 파일이 자동으로 다운로드됩니다. 쉽게 액세스할 수 있는 위치에 저장합니다.
14. 인스턴스 시작을 클릭합니다.

인스턴스가 성공적으로 생성되었습니다!
③ DMS에 대한 IAM 정책 및 역할 생성
이번 단계에서는 IAM 정책 및 역할 DMS가 대상 S3 버킷에 쓰기를 허용합니다.
- AWS Management Console에서 상단 검색 표시줄을 사용하여 IAM을 검색하고 선택합니다.
- 왼쪽 메뉴에서 정책을 클릭한 다음 정책 생성을 클릭합니다.
- 기본적으로 시각적 편집기가 선택되어 있으므로 JSON 탭을 클릭하여 텍스트 항목으로 변경합니다.
- 텍스트 상자의 상용구 코드를 다음 정책 정의로 바꿉니다. 버킷 이름의 <initials>을 3장 AWS Data Engineers Toolkit에서 생성한 올바른 랜딩 존 버킷 이름으로 바꾸십시오.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::dataeng-landing-zone-<initials>",
"arn:aws:s3:::dataeng-landing-zone-<initials>/*"
]
}
]
}
5. 다음: 태그를 클릭한 후 다음: 검토를 클릭합니다.
6. 제공설명 정책 이름(예:DataEngDMSLandingS3BucketPolicy)으로 변경하고 정책 생성을 클릭합니다.

7. 왼쪽 메뉴에서 역할을 클릭한 다음 역할 만들기를 클릭합니다.
8. 신뢰할 수 있는 엔터티 유형 선택에서 AWS 서비스가 선택되어 있는지 확인합니다.
9. 사용 사례 기타 목록에서 DMS를 선택한 후 다음을 클릭하십시오.
10. 6단계에서 생성한 정책을 검색하여 선택한 후 다음을 클릭합니다.
11. DataEngDMSLandingS3BucketRole과 같이 설명이 포함된 역할 이름을 작성하고 역할 생성을 클릭합니다.

12. 새로 만든 역할의 역할 ARN 속성을 쉽게 액세스할 수 있는 위치에 복사하여 붙여넣습니다. 다음 섹션에서 필요합니다.
필요한 IAM 권한을 생성했습니다. 다음 단계로 넘어가 봅시다.
④ DMS 설정 구성 및 MySQL에서 S3로 전체 로드 수행
이 섹션에서는 DMS 복제 생성인스턴스(소스 엔드포인트에 연결하고, 데이터를 검색하고, 대상 엔드포인트에 쓰는 관리형 EC2 인스턴스), 소스 및 대상 엔드포인트도 구성합니다. 그런 다음 마이그레이션을 위한 구성 설정을 제공하는 데이터베이스 마이그레이션 작업을 생성합니다.



- AWS Management Console에서 상단 검색 표시줄을 사용하여 DMS를 검색하고 Database Migration Service를 클릭합니다.
- 왼쪽 메뉴에서 복제 인스턴스를 클릭합니다 .
- 페이지 상단에서 복제 인스턴스 생성을 클릭합니다 .
- 복제 인스턴스의 이름을 제공하십시오. (예: mysql-s3-replication)
- 인스턴스 클래스에서 dms.t3.micro를 선택합니다.
- 할당된 스토리지에 10을 입력합니다 (복제하려는 데이터베이스는 매우 작기 때문에 10GB면 충분한 공간입니다).
- VPC 드롭다운에서 기본 VPC를 선택합니다.
- 다중 AZ의 경우 '개발 또는 테스트 워크로드(단일 AZ)'를 선택합니다.
- 나머지는 모두 기본값으로 두고 복제 인스턴스 생성을 클릭합니다.


- 왼쪽 메뉴에서 Endpoints를 클릭합니다 .
- 오른쪽 상단에서 엔드포인트 생성을 클릭합니다 .
- 엔드포인트 유형에서 소스 엔드포인트를 선택한 다음 RDS DB 인스턴스 선택 상자를 클릭합니다.
- RDS 인스턴스의 경우 드롭다운 목록을 사용하여 이전에 생성한 MySQL 데이터베이스를 선택합니다.
- 엔드포인트 구성에서 엔드포인트 데이터베이스에 대한 액세스에 대해 수동으로 액세스 정보 제공을 선택합니다.
- Password에는 ①새 MySQL 데이터베이스 인스턴스 생성 섹션의 9단계 에서 데이터베이스에 대해 설정한 암호를 적습니다.
- 오른쪽 하단에서 엔드포인트 생성을 선택합니다.


- 이제 소스 엔드포인트를 생성했으므로 오른쪽 상단의 엔드 포인트 생성을 클릭하여 대상 엔드포인트를 생성할 수 있습니다.
- 엔드포인트 유형에서 대상 엔드포인트를 선택합니다 .
- 엔드포인트 식별자에 s3-landing-zone-sakilia-csv와 같은 엔드포인트 이름을 입력합니다.
- 대상 엔진의 경우 드롭다운 목록에서 Amazon S3를 선택합니다.
- 서비스 액세스 역할 ARN에 아까 기록해 뒀던 IAM에 대한 Amazon 리소스 이름 (ARN)을 입력합니다.
- Bucket name에는 3장 AWS Data Engineers Toolkit에서 생성한 랜딩 존 버킷의 이름을 입력합니다 (예: dataeng-landing-zone-<initials> ).
- 버킷 폴더 에 sakila-db를 입력합니다.
- 엔드포인트 설정을 확장하고 새 설정 추가를 클릭합니다. 설정 목록에서 'AddColumnName'을 선택하고 값 유형을 True로 지정합니다.


- 데이터베이스 마이그레이션 태스크 생성을 클릭합니다.
- 태스크 생성을 클릭합니다.
- 작업 식별자에 dataeng-mysql-s3-sakila-task와 같이 작업을 설명하는 이름을 제공합니다.
- 복제 인스턴스에서 mysql-s3-replication과 같이 이전 섹션의 4단계에서 생성한 인스턴스를 선택합니다.
- 소스 데이터베이스 엔드포인트에 대해 방금 생성한 소스 엔드포인트 (예: dataeng-mysql-1 ) 을 선택합니다 .
- 대상 데이터베이스 엔드포인트에서 방금 생성한 대상 엔드포인트( 예: s3-landing-zone-sakilia-csv)를 선택합니다 .
- 마이그레이션 유형에 대해 드롭다운에서 기존 데이터 마이그레이션을 선택합니다.
- 작업 설정의 기본값은 그대로 둡니다.
- 테이블 매핑의 경우 선택 규칙 아래에서 새 선택 규칙 추가를 클릭합니다.
- 스키마에 대해 스키마 입력을 선택합니다. 스키마 이름과 테이블 이름은 % 로 설정합니다.
- 선택 규칙 및 기타 모든 섹션의 기본값을 그대로 두고 작업 만들기를 클릭합니다.
- 작업이 생성되면 전체 로드가 자동으로 시작되고 데이터가 MySQL 인스턴스에서 Amazon S3로 로드됩니다. 작업 식별자를 클릭하고 테이블 통계 탭을 검토하여 진행 상황을 모니터링합니다.
랜딩 존 버킷에 기록된 모든 CSV 파일에 대해 이전에 구성된 S3 이벤트는 DMS가 로드하는 각 파일에 대해 트리거됩니다. 이렇게 하면 CLEAN ZONE 버킷에 있는 각 파일의 새 Parquet 버전을 생성하는 3장에서 생성한 Lambda 함수가 실행됩니다 . 이렇게 하면 AWS Glue 데이터 카탈로그에 각 테이블도 등록됩니다.
⑤ Amazon Athena로 데이터 쿼리
이제 Amazon Athena 서비스를 사용하여 새로 수집된 데이터를 쿼리할 수 있습니다.


- 먼저 Athena 쿼리 결과를 저장할 새 Amazon S3 폴더를 생성해야 합니다. AWS Management Console에서 상단 검색 표시줄을 사용하여 S3를 검색하고 선택합니다.
- 버킷 생성을 클릭하고 버킷 이름에 athena-query-results-<INITIALS>를 입력합니다. AWS 리전이 이전 실습에서 사용한 리전으로 설정되어 있는지 확인합니다. 다른 모든 기본값은 그대로 두고 버킷 만들기를 클릭합니다.
- AWS Management Console에서 상단 검색 표시줄을 사용하여 Athena를 검색하고 선택합니다.
- 왼쪽 패널을 확장하고 쿼리 편집기를 클릭합니다.
- Athena 대시보드 페이지에서 쿼리 편집기 탐색을 클릭한 다음 설정 탭을 클릭합니다.
- 설정 탭에서 관리를 클릭하고 쿼리 결과 위치에 방금 생성한 버킷의 경로를 입력한 다음 저장을 클릭합니다.
- 편집기 탭으로 돌아가서 데이터베이스 드롭다운에서 sakila를 선택합니다.
- 새 쿼리 창 에서 select * from film limit 20을 실행합니다.
- 이 쿼리는 Sakila 데이터베이스에서 처음 20개의 가상 영화 결과를 반환합니다.
- DMS 복제 인스턴스는 실행되는 동안 시간당 비용이 저렴합니다. 이제 Amazon S3에 대한 데이터베이스 복제를 완료하고 Athena로 데이터를 쿼리하여 이 작업의 성공을 확인했으므로 복제 인스턴스를 삭제할 수 있습니다. DMS 서비스를 열고 왼쪽에서 데이터베이스 마이그레이션 작업을 클릭합니다. 연결된 복제 인스턴스를 삭제하기 전에 작업을 삭제해야 하므로 작업을 선택하고 작업 메뉴에서 삭제를 클릭한 다음 팝업 상자에서 삭제를 확인합니다.
- 복제 작업이 삭제되면 왼쪽에서 복제 인스턴스를 클릭합니다. 이전에 생성한 복제 인스턴스를 선택한 다음 작업 메뉴에서 삭제를 선택합니다. 팝업 상자에서 삭제를 클릭하여 복제 인스턴스를 삭제할 것인지 확인합니다.
축하해요! MySQL 데이터베이스를 S3 기반 데이터 레이크에 성공적으로 복제했습니다.
태스크 생성에서 오류가 있었는지 sakila 데이터베이스가 생성되지 않아서 쿼리를 돌릴 때 에러가 발생했습니다. 해결 방법을 찾으면 다시 블로깅해 보겠습니다.

'AWS' 카테고리의 다른 글
| [실습] Amazon Comprehend로 리뷰 검토 (0) | 2023.03.25 |
|---|---|
| [13장] 인공 지능 및 머신 러닝 활성화 (0) | 2023.03.24 |
| [실습] AWS Step Function을 사용하여 데이터 파이프라인 오케스트레이션 (0) | 2023.03.14 |
| [AWS 데이터엔지니어링] 5장 데이터 엔지니어링 파이프라인 설계 (0) | 2023.02.07 |
| [AWS 데이터엔지니어링] 3장 데이터 엔지니어 도구 키트 (0) | 2023.01.25 |




댓글