-
[BigQuery] 다면적인 축을 사용해 데이터 집약하기SQL 2022. 5. 6. 02:17
<데이터분석을 위한 SQL 레시피> 4장 10강을 참고해 실습한 내용입니다.
이전 글의 실습 내용은 꺾은선 그래프로 매출의 추이를 나타내는 것이었다. 이번 글에서는 매출의 시계열뿐만 아니라 상품의 카테고리, 가격 등을 조합해 데이터의 특징을 추출해서 리포팅을 하는 방법을 소개하고자 한다.
#샘플 데이터
이번 실습에서는 EC 사이트를 가정해서 'purchase_detail_log'라는 샘플 데이터를 기반으로 한다. 이 EC 사이트는 한 번의 주문으로 여러 상품을 구매할 수 있는데, 하나의 order_id에 item_id, price, category, sub_category 등 여러 정보가 포함되어 있다.
purchase_detail_log 테이블을 생성하자.
DROP TABLE IF EXISTS expanded-lock-349311.lec10.purchase_detail_log; CREATE TABLE expanded-lock-349311.lec10.purchase_detail_log( dt string(255) , order_id integer , user_id string(255) , item_id string(255) , price integer , category string(255) , sub_category string(255) ); INSERT INTO expanded-lock-349311.lec10.purchase_detail_log VALUES ('2017-01-18', 48291, 'usr33395', 'lad533', 37300, 'ladys_fashion', 'bag') , ('2017-01-18', 48291, 'usr33395', 'lad329', 97300, 'ladys_fashion', 'jacket') , ('2017-01-18', 48291, 'usr33395', 'lad102', 114600, 'ladys_fashion', 'jacket') , ('2017-01-18', 48291, 'usr33395', 'lad886', 33300, 'ladys_fashion', 'bag') , ('2017-01-18', 48292, 'usr52832', 'dvd871', 32800, 'dvd' , 'documentary') , ('2017-01-18', 48292, 'usr52832', 'gam167', 26000, 'game' , 'accessories') , ('2017-01-18', 48292, 'usr52832', 'lad289', 57300, 'ladys_fashion', 'bag') , ('2017-01-18', 48293, 'usr28891', 'out977', 28600, 'outdoor' , 'camp') , ('2017-01-18', 48293, 'usr28891', 'boo256', 22500, 'book' , 'business') , ('2017-01-18', 48293, 'usr28891', 'lad125', 61500, 'ladys_fashion', 'jacket') , ('2017-01-18', 48294, 'usr33604', 'mem233', 116300, 'mens_fashion' , 'jacket') , ('2017-01-18', 48294, 'usr33604', 'cd477' , 25800, 'cd' , 'classic') , ('2017-01-18', 48294, 'usr33604', 'boo468', 31000, 'book' , 'business') , ('2017-01-18', 48294, 'usr33604', 'foo402', 48700, 'food' , 'meats') , ('2017-01-18', 48295, 'usr38013', 'foo134', 32000, 'food' , 'fish') , ('2017-01-18', 48295, 'usr38013', 'lad147', 96100, 'ladys_fashion', 'jacket') ;

purchase_detail_log 1. 카테고리별 매출과 소계 계산하기 UNION ALL 구문, ROLLUP 구문
합계는 '무언가를 더한 것', 소계는 '일부를 더한 것', 총계는 '전체를 더한 것'이다. 이를 구분해서 이해하고 카테고리의 소계와 총계를 한 번에 출력해보자. 계층별로 집계한 결과를 같은 콜롬이 되게 변환한 뒤 UNION ALL 구문으로 하나의 테이블로 합치면 된다.
WITH sub_category_amount AS( --소 카테고리의 매출 집계하기 SELECT category AS category ,sub_category AS sub_category ,SUM(price) AS amount FROM expanded-lock-349311.lec10.purchase_detail_log GROUP BY category,sub_category ) ,category_amount AS( --대 카테고리의 매출 집계하기 SELECT category ,'all' AS sub_category ,SUM(price) AS amount FROM expanded-lock-349311.lec10.purchase_detail_log GROUP BY category ) ,total_amount AS( --전체 매출 집계하기 SELECT 'all' AS category ,'all'AS sub_category ,SUM(price) AS amount FROM expanded-lock-349311.lec10.purchase_detail_log ) SELECT category,sub_category,amount FROM sub_category_amount UNION ALL SELECT category,sub_category,amount FROM category_amount UNION ALL SELECT category,sub_category,amount FROM total_amount ;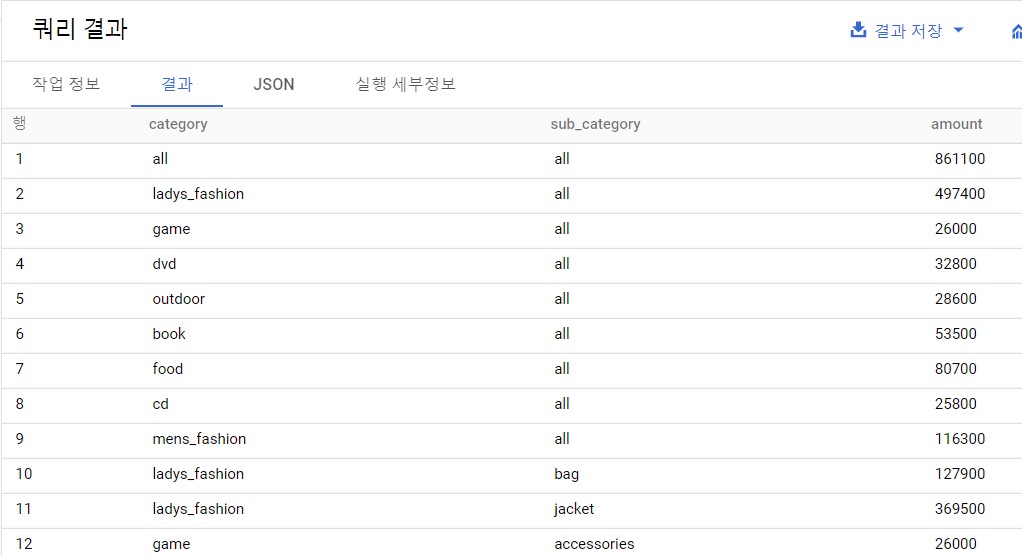

카테고리별 매출과 소계를 동시에 구하는 쿼리 이와 같은 SQL을 사용하면 하나의 쿼리로 카테고리별 소계와 총계를 동시에 계산할 수 있다.
하지만 UNION ALL을 사용해 테이블을 결합하는 방법은 테이블을 여러 번 불러오고, 데이터를 결합하는 비용이 발생해 성능이 좋지 않다.
PostgreSQL, Hive, SparkSQL에서는 'ROLLUP'을 사용해서 조금 더 쉽고 성능 좋은 쿼리를 만들 수 있다. 하지만 지금은 BigQuery를 사용하고 있으므로 결과를 확인할 수는 없지만, 쿼리문을 한번 작성해보겠다.
SELECT COALESCE(category,'all') AS category ,COALESCE(sub_category,'all') AS sub_category ,SUM(price) AS amount FROM expanded-lock-349311.lec10.purchase_detail_log GROUP BY ROLLUP(category,sub_category) ;이렇게 훨씬 짧은 쿼리로 카테고리별 매출과 소계를 동시에 구할 수 있다.
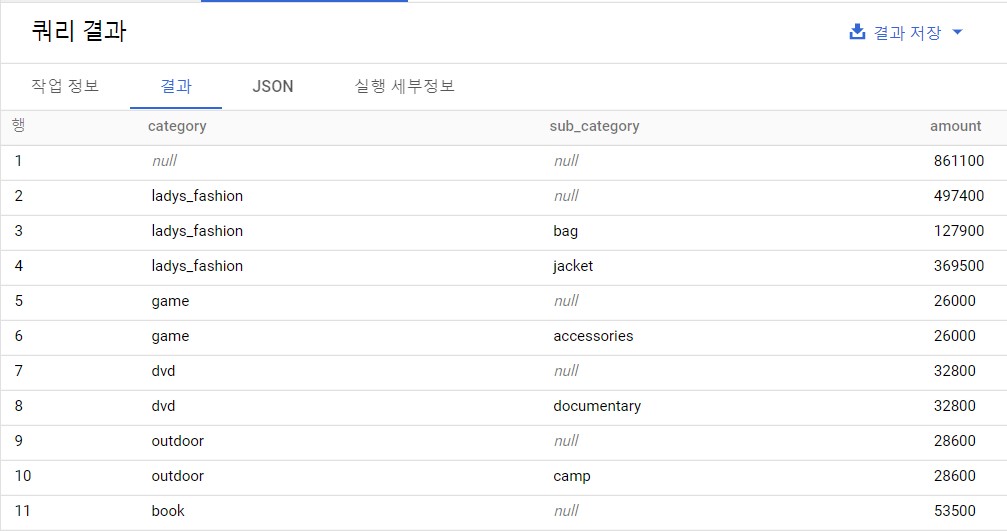

ROLLUP을 사용해 카테고리별 매출과 소계를 동시에 구하는 쿼리 ROLLUP을 사용하면 소계를 계산할 때 레코드 집계 키가 NULL이 되는데, COALESCE 함수로 NULL을 문자열 'all'로 변환할 수 있다.
2. ABC 분석으로 잘 팔리는 상품 판별하기 SUM(~), OVER(ORDER BY~)
ABC 분석은 재고 관리 등에서 사용하는 분석 방법이다. 매출 중요도에 따라 상품을 나누고, 그에 맞게 전략을 만들 때 사용한다.
2017년 1월 한 달 동안의 구매 로그를 기반으로, 매출 구성비누계와 ABC 등급을 계산하는 쿼리를 만들어보자.
1. BETWEEN ~AND 구문으로 원하는 시간에 있는 구매 로그를 압축하고 SUM 함수로 상품 카테고리마다 매출을 계산하기
2. SUM(~) OVER(ORDER BY~) 함수로 전체 매출에 대해 항목별 매출 구성비와 구성비누계를 계산하기(이때, amount에 100.0을 곱하여 정수를 실수로 변환해서 비율을 구하는 방법을 사용)
3. WHEN~BETWEEN~AND~THEN 구문으로 구성비누계를 기준으로 상위 '0~70%', '70~90%', '90~100%'의 등급 나누기
WITH monthly_sales AS( SELECT category --항목별 매출 계산하기 ,SUM(price) AS amount FROM expanded-lock-349311.lec10.purchase_detail_log --대상 1개월 동안의 로그를 조건으로 걸기 WHERE dt BETWEEN '2017-01-01' AND '2017-01-31' GROUP BY category ) ,sales_composition_ratio AS( SELECT category ,amount --구성비: 100.0*<항목별 매출>/<전체 매출> ,100.0*amount/SUM(amount) OVER() AS composition_ratio --구성비누계: 100.0*<항목별 구계 매출>/<전체 매출> ,100.0*SUM(amount) OVER(ORDER BY amount DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) /SUM(amount) OVER() AS cumulative_ratio FROM monthly_sales ) SELECT * --구성비누계 범위에 따라 순위 붙이기 ,CASE WHEN cumulative_ratio BETWEEN 0 AND 70 THEN 'A' WHEN cumulative_ratio BETWEEN 70 AND 90 THEN 'B' WHEN cumulative_ratio BETWEEN 90 AND 100 THEN 'C' END AS abc_rank FROM sales_composition_ratio ORDER BY amount DESC ;
매출 구성비누계와 ABC 등급을 계산하는 쿼리 3. 팬 차트로 상품의 매출 증가율 확인하기 FIRST_VALUE 윈도 함수
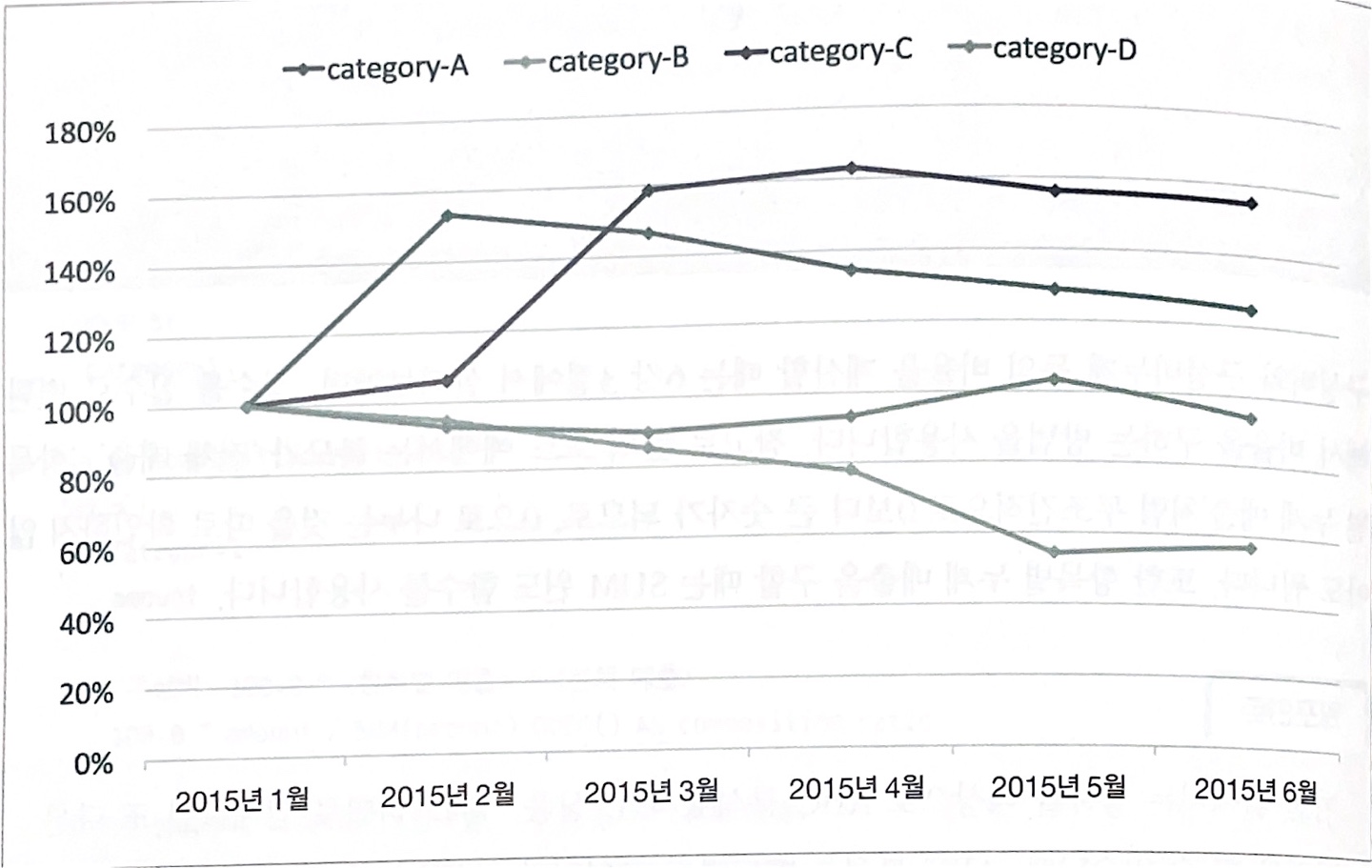
팬 차트 팬 차트는 어떤 기준 시점을 100%로 두고, 이후의 숫자 변동을 확인할 수 있게 해주는 그래프다. 추이를 판단하는 경우에 작은 변화는 그래프에서 변화를 확인하기가 힘들다. 하지만 팬 차트를 사용하면 변화가 백분율로 표시되기 때문에, 작은 변화도 쉽게 인지하고 상황을 판단할 수 있다.
이번에는 팬 차트 작성을 위한 데이터를 집약하기 위해, 2017년 1월의 카테고리별 매출을 기준으로 이후의 변화 비율을 집계해보겠다.
1. 날짜 데이터를 기반으로 SUBSTR 함수를 사용해연과 열의 값 추출하기
2. 구한 매출을 시계열 순서로 정렬하고, 팬 차트 작성을 위한 기준이 되는 월 매출을 기준으로 비율 구하기(기준이 되는 매출이 시계열로 정렬했을 때 가장 첫 월의 매출이므로, FIRST_VALUE 윈도 함수를 사용함)
WITH daily_category_amount AS( SELECT dt ,category ,substr(dt,1,4) AS year ,substr(dt,6,2) AS month ,substr(dt,9,2) AS date ,SUM(price) AS amount FROM expanded-lock-349311.lec10.purchase_detail_log GROUP BY dt,category ) ,monthly_category_amount AS( SELECT concat(year,'-',month) AS year_month ,category ,SUM(amount) AS amount FROM daily_category_amount GROUP BY year,month,category ) SELECT year_month ,category ,amount ,FIRST_VALUE(amount) OVER(PARTITION BY category ORDER BY year_month,category ROWS UNBOUNDED PRECEDING) AS base_amount ,100.0 *amount /FIRST_VALUE(amount) OVER(PARTITION BY category ORDER BY year_month,category ROWS UNBOUNDED PRECEDING) AS rate FROM monthly_category_amount ORDER BY year_month,category ;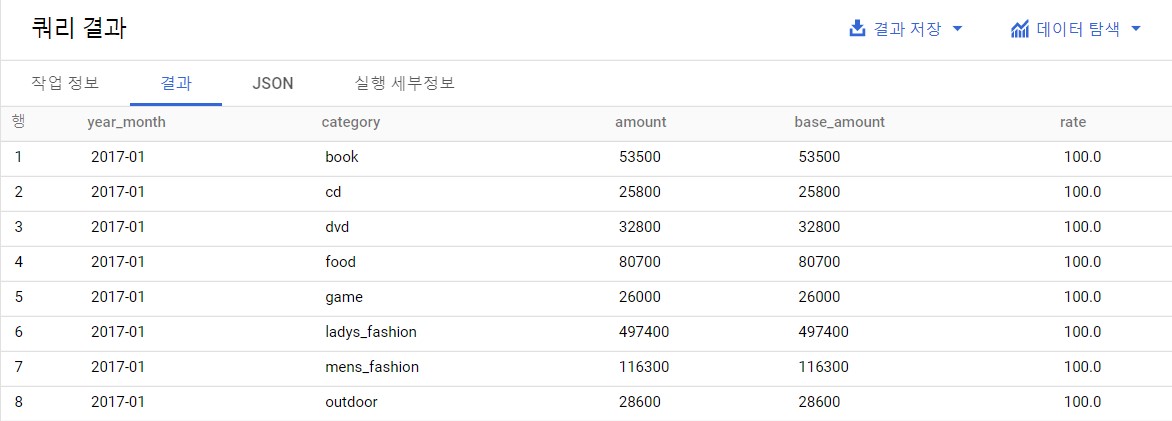
팬 차트 작성 때 필요한 데이터를 구하는 쿼리 쿼리 실행 결과를 보면, base_amount 콜롬에 FIRST_VALUE 윈도 함수를 사용해 구한 2017년 1월의 매출을 넣었고, 그러한 base_amount에 대한 비율을 rate 콜롬에 계산했다.
4. 히스토그램으로 구매 가격대 집계하기 WIDTH_BUCKET 함수
히스토그램은 가로 축에 단계(데이터의 범위), 세로 축에 도수(데이터의 개수)를 나타내는 그래프다.

히스토그램을 사용하면 데이터가 어떻게 분산되어 있는지 한눈에 볼 수 있다. 위 그림처럼 평균은 모두 같지만, 히스토그램을 확인하면 데이터의 분포가 다르다는 것을 알 수 있다.
#히스토그램 만드는 방법
히스토그램을 만들려면 범위를 계급으로 나누고 각 계급의 상한과 하한 및 각 계급에 들어가는 데이터 개수(도수)를 정리한 도수분포표가 있어야 한다. 도수 분포표를 그래프로 그리면 히스토그램이 되는데, 막대 사이에 공백을 넣지 않고 그린다.
#임의의 계층 수로 히스토그램 만들기
구매 로그 샘플을 기반으로 매출 상품의 최대, 최소 가격을 구하고 범위를 10등분하는 히스토그램을 만들어보자.
1. MAX 함수와 MIN 함수를 사용해서 매출 금액의 최댓값(max_amount)과 최솟값(min_amount), 금액 범위(range_amount) 구하기
2. WITH 구문을 사용해서 이 값을 계산한 테이블을 stats로 정의하기
3. 계층 수(bucket_num) 정의하기
WITH stats AS( SELECT --금액의 최댓값 MAX(price) AS max_price --금액의 최솟값 ,MIN(price) AS min_price --금액의 범위 ,MAX(price)-MIN(price) AS range_price --계층 수 ,10 AS bucket_num FROM expanded-lock-349311.lec10.purchase_detail_log ) SELECT * FROM stats ;
최댓값, 최솟값, 범위를 구하는 쿼리 이번에는 최소 금액에서 최대 금액의 범위를 계층으로 분할해보자.
1. 매출 금액에서 최소 금액을 뺀 뒤 계층을 판정하기 위한 정규화 금액(diff) 계산하기
2. 첫 번째 계층의 범위(bucket_range) 구하기: 금액 범위(range_price)/계급 수(bucket_num)
3. 계층 판정하기: (정규화 금액/계급 범위)를 FLOOR 함수를 사용해 소수 자리 버리기
WITH stats AS( SELECT MAX(price) AS max_price ,MIN(price) AS min_price ,MAX(price)-MIN(price) AS range_price ,10 AS bucket_num FROM expanded-lock-349311.lec10.purchase_detail_log ) ,purchase_log_with_bucket AS( SELECT price ,min_price --정규화 금액: 대상 금액에서 최소 금액 뺀 것 ,price-min_price AS diff --계층 범위: 금액 범위를 계층 수로 나눈 것 ,1.0*range_price/bucket_num AS bucket_range --계층 판정: FLOOR(정규화금액/계층범위) ,FLOOR( 1.0*(price-min_price) /(1.0*range_price/bucket_num) --index가 1부터 시작하므로 1만큼 더하기 )+1 AS bucket FROM expanded-lock-349311.lec10.purchase_detail_log,stats ) SELECT * FROM purchase_log_with_bucket ORDER BY price ;

데이터의 계층을 구하는 쿼리 참고로 이 출력 결과에서는 계급 범위를 10으로 저장했기 때문에 최댓값인 116300은 '11'로 판정된다. 계급 판정 로직에 '<계급 하한 이상>~<계급 상한 미만>'을 사용해서 계급 10의 범위가 116300 미만으로 잡혀, 116300은 계급 10의 범위를 넘기 때문이다.
그럼 이번에는 모든 레코드가 지정한 범위 내부에 들어갈 수 있게 해보자.
stats 테이블의 정의에서 계급 상한을 <금액의 최댓값>+1로 해서, 모든 레코드가 계급 상한 미만이 되게 만들면 된다.
WITH stats AS( SELECT --<금액의 최댓값>+1 MAX(price)+1 AS max_price --금액의 최솟값 ,MIN(price) AS min_price --<금액의 범위>+1(실수) ,MAX(price)+1-MIN(price) AS range_price --계층 수 ,10 AS bucket_num FROM expanded-lock-349311.lec10.purchase_detail_log ) ,purchase_log_with_bucket AS( SELECT price ,min_price ,price-min_price AS diff ,1.0*range_price/bucket_num AS bucket_range ,FLOOR( 1.0*(price-min_price) /(1.0*range_price/bucket_num) )+1 AS bucket FROM expanded-lock-349311.lec10.purchase_detail_log,stats ) SELECT * FROM purchase_log_with_bucket ORDER BY price ;

계급 상한 값을 조정한 쿼리 이렇게 계층 상한값을 +1 조정한 쿼리의 결과를 보면 소수점이 들어가버리지만, 최댓값 레코드까지 포함해서 1~10의 계층으로 구분되었다.
마지막으로, 구한 계층을 사용해 도수(데이터의 개수)를 계산하자.
1. 각 계층의 하한과 상한 계산하기
2. COUNT 함수를 사용해 도수 세기
3. SUM 함수를 사용해 합계 금액 계산하기
WITH stats AS( SELECT MAX(price)+1 AS max_price ,MIN(price) AS min_price ,MAX(price)+1-MIN(price) AS range_price ,10 AS bucket_num FROM expanded-lock-349311.lec10.purchase_detail_log ) ,purchase_log_with_bucket AS( SELECT price ,min_price ,price-min_price AS diff ,1.0*range_price/bucket_num AS bucket_range ,FLOOR( 1.0*(price-min_price) /(1.0*range_price/bucket_num) )+1 AS bucket FROM expanded-lock-349311.lec10.purchase_detail_log,stats ) SELECT bucket --계층의 하한과 상한 계산하기 ,min_price+bucket_range*(bucket-1) AS lower_limit ,min_price+bucket_range*bucket AS upper_limit --도수 세기 ,COUNT(price) AS num_purchase --합계 금액 계산하기 ,SUM(price) AS total_amount FROM purchase_log_with_bucket GROUP BY bucket,min_price,bucket_range ORDER BY bucket ;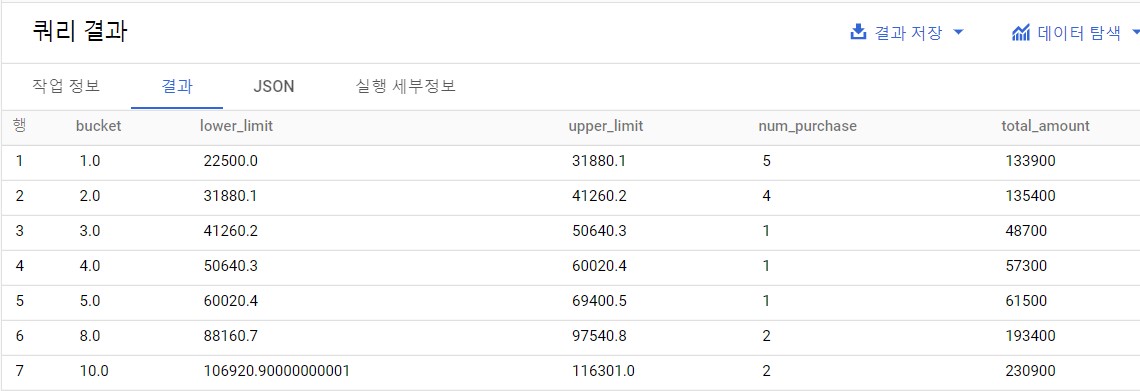
히스토그램을 구하는 쿼리 #임의의 계층 너비로 히스토그램 작성하기
위에서처럼 가격의 상한과 하한 기준으로도 최적의 범위를 구할 수 있지만, 소수점으로 계층을 구분한 것은 한눈에 이해하기 쉽지 않다.
상한과 하한을 조정한 코드를 변경해서 금액의 최댓값, 최솟값, 금액 범위 등의 고정값을 기반으로 임의의 계층 너비로 변경할 수 있는 기능을 넣어보자.
0~120,000원의 범위를 10개의 계층으로 구분하는 쿼리를 만들자.
WITH stats AS( SELECT --금액의 최댓값 120000 AS max_price --금액의 최솟값 ,0 AS min_price --금액의 범위 ,120000 AS range_price --계층 수 ,10 AS bucket_num FROM expanded-lock-349311.lec10.purchase_detail_log ) ,purchase_log_with_bucket AS( SELECT price ,min_price ,price-min_price AS diff ,1.0*range_price/bucket_num AS bucket_range ,FLOOR( 1.0*(price-min_price) /(1.0*range_price/bucket_num) )+1 AS bucket FROM expanded-lock-349311.lec10.purchase_detail_log,stats ) SELECT bucket --계층의 하한과 상한 계산하기 ,min_price+bucket_range*(bucket-1) AS lower_limit ,min_price+bucket_range*bucket AS upper_limit --도수 세기 ,COUNT(price) AS num_purchase --합계 금액 계산하기 ,SUM(price) AS total_amount FROM purchase_log_with_bucket GROUP BY bucket,min_price,bucket_range ORDER BY bucket ;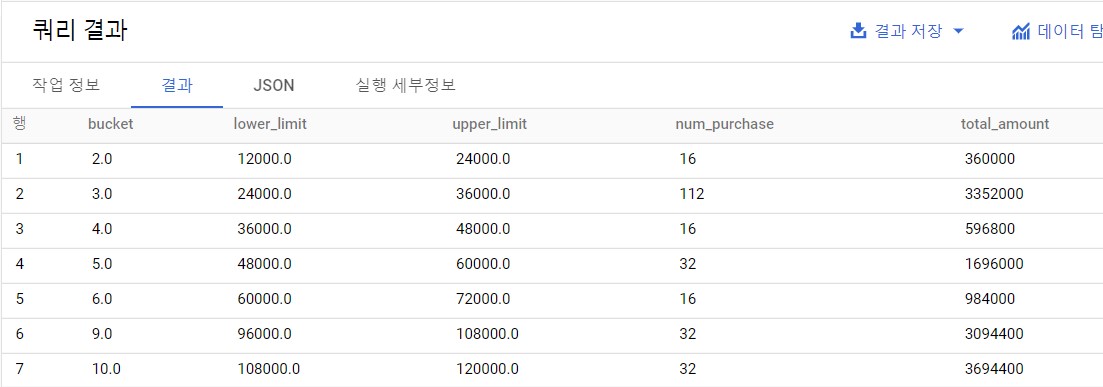
히스토그램의 상한과 하한을 수동으로 조정한 쿼리 출력 결과로 12,000원 단위로 구분된 계층 히스토그램 데이터가 만들어졌다.
#히스토그램이 나누어진 경우
히스토그램 산이 2개로 나누어진 경우에는 서로 다른 모집단을 기반으로 하나의 데이터를 도출한 경우일 수 있다. 이럴 때는 데이터에 여러 조건을 걸어 필터링해서 확인해본다.
'SQL' 카테고리의 다른 글
[MySQL] 프로그래머스 Lv 3. 조건별로 분류하여 주문상태 출력하기 정답풀이 (0) 2023.08.12 [BigQuery] 웹사이트에서의 행동을 파악하는 데이터 추출하기 (0) 2022.05.20 [BigQuery] 시계열 기반으로 데이터 집계하기 (0) 2022.05.06 [Oracle] WHERE 절을 이용한 조건 검색 (0) 2022.04.18 [Oracle] SELECT 명령문을 사용하여 다양한 방법으로 데이터 출력하기 (0) 2022.04.15