-
[ML경진대회] 범주형 데이터 이진분류-탐색적 데이터 분석(2)ML.DL 2022. 10. 2. 18:00
책 <머신러닝, 딥러닝 문제해결 전략> 7장을 실습한 내용입니다.
지난 실습에 이어서, 이번에는 데이터를 시각화하여 어떤 피처가 중요하고 어떤 고윳값이 타깃값에 영향을 많이 주는지 알아보자!
2-2. 데이터 시각화
먼저 시각화 라이브러리를 불러오고, 그래프를 그려보자.
import seaborn as sns import matplotlib as mpl import matplotlib.pyplot as plt %matplotlib inline① 타깃값 분포
분포도 중 하나인 카운트플롯으로 타깃값 0과 1의 개수를 파악하자. 카운트플롯은 범주형 데이터의 개수를 확인할 때 주로 사용한다.
mpl.rc('font', size=15) #폰트 크기 설정 plt.figure(figsize=(7,6)) #Figure 크기 설정 #타깃값 분포 카운트플롯 ax=sns.countplot(x='target', data=train) ax.set_title('Target Distribution');countplot()의 x 파라미터에 타깃값('target')을 전달했고, data 파라미터에 훈련 데이터(train)를 전달했다. 그러면 train['target']에서 고윳값별로 데이터가 몇 개인지 카운트플롯으로 그려준다.
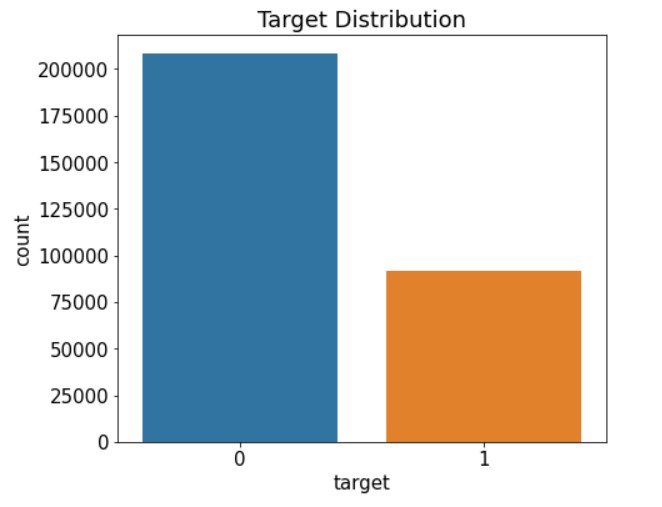
타깃값 0이 타깃값 1보다 훨씬 많은 걸 볼 수 있다!
이번에는 각 값의 비율을 그래프 상단해 표시해서 더 유용한 그래프를 그려볼 것이다. 비율을 표시하려면 글자를 쓸 위치를 구해야 하는데, ax.patches를 이용해 사각형의 높이, 너비, 왼쪽 테두리의 x축의 위치를 먼저 구해야 한다.rectangle=ax.patches[0] #첫 번째 Rectangle 객체 print('사각형 높이:',rectangle.get_height()) print('사각형 너비:',rectangle.get_width()) print('사각형 왼쪽 테두리의 x축 위치:',rectangle.get_x())
이번에는 비율을 표시할 위치를 계산해보자. 막대 바로 위에 가운데 정렬하여 표시하려고 한다.print('텍스트 위치의 x좌표:', rectangle.get_x()+rectangle.get_width()/2.0) print('텍스트 위치의 y좌표:', rectangle.get_height()+len(train)*0.001)
텍스트 표시 위치를 구하는 방법을 알았으니, 이제 비율을 표시해주는 코드를 함수로 구현한 후, 그 함수를 사용해 카운트플롯을 다시 그려보자!def write_percent(ax,total_size): '''도형 객체를 순회하며 막대 상단에 타깃값 비율 표시''' for patch in ax.patches: height=patch.get_height() #도형 높이(데이터 개수) width=patch.get_width() #도형 너비 left_coord=patch.get_x() #도형 왼쪽 테두리와 x축 위치 percent=height/total_size*100 #타깃값 비율 #(x,y) 좌표에 텍스트 입력 ax.text(x=left_coord+width/2.0, #x축 위치 y=height+total_size*0.001, #y축 위치 s=f'{percent:1.1f}%', #입력 텍스트 ha='center') #가운데 정렬 plt.figure(figsize=(7,6)) ax=sns.countplot(x='target',data=train) write_percent(ax,len(train)) #비율 표시 ax.set_title('Target Distribution');
각 막대 위에 비율이 표시돼서 타깃값 0과 1이 약 7대 3 비율인 것을 바로 파악할 수 있게 되었다!
② 이진피처 분포
이번에는 이진 피처의 분포를 타깃값별로 따로 그려볼 것이다. 범주형 피처의 타깃값 분포를 고윳값별로 구분해 그려보는 건 분류 문제에서 종종 쓰는 방법인데, 특정 고윳값이 특정 타깃값에 치우치는지 확인할 수 있기 때문이다.
피처별로 총 5개의 그래프가 출력될 것이기 때문에, 여러 그래프를 격자 형태로 배치하는 GridSpec을 사용해서 그려보자!import matplotlib.gridspec as gridspec #여러 그래프를 격자 형태로 배치 ⓐ #3행 2열 틀(Figure) 준비 mpl.rc('font',size=12) grid=gridspec.GridSpec(3,2) #그래프(서브플롯)를 3행 2열로 배치 plt.figure(figsize=(10,16)) #전체 Figure 크기 설정 plt.subplots_adjust(wspace=0.4, hspace=0.3) #서브플롯 간 좌우/상하 여백 설정 ⓑ #서브플롯 그리기 bin_features=['bin_0','bin_1','bin_2','bin_3','bin_4'] #피처 목록 ⓒ for idx, feature in enumerate(bin_features): # ⓓ ax=plt.subplot(grid[idx]) # ⓔ #ax축에 타깃값 분포 카운트플롯 그리기 ⓕ sns.countplot(x=feature, data=train, hue='target', palette='pastel', #그래프 색상 설정 ax=ax) ax.set_title(f'{feature} Distribution by Target') #그래프 제목 설정 ⓖ write_percent(ax, len(train)) #비율 표시 ⓗⓐ 서브플롯을 3행 2열로 배치한 GridSpec 객체를 grid 변수에 할당한다. 나중에 grid[0], grid[1],... 과 같이 원하는 서브플롯을 지정할 수 있다.
ⓑ subplots_adjust()를 활용해 좌우, 상하 간격을 따로 조정할 수 있다.
ⓒ 이진 피처의 목록을 bin_features에 담은 후, ⓓ for문을 활용해 각각의 카운트플롯을 그린다.
ⓔ grid에서 이번 서브플롯을 그릴 위치를 ax축으로 지정하고, ⓕ ax축에 타깃값 분포 카운트플롯을 그린 다음, ⓖ 그래프의 제목을 설정하고, ⓗ 비율을 표시한다.
ⓕ에서 각 파라미터의 의미는 아래와 같다.- x: 피처
- data: 전체 데이터셋
- hue: 세부적으로 나눠 그릴 기준 피처인데, 여기서는 타깃값을 전달했다.
- palette: 그래프 색상맵이다. pastel은 파스텔톤이다.
- ax: 그래프를 그릴 축
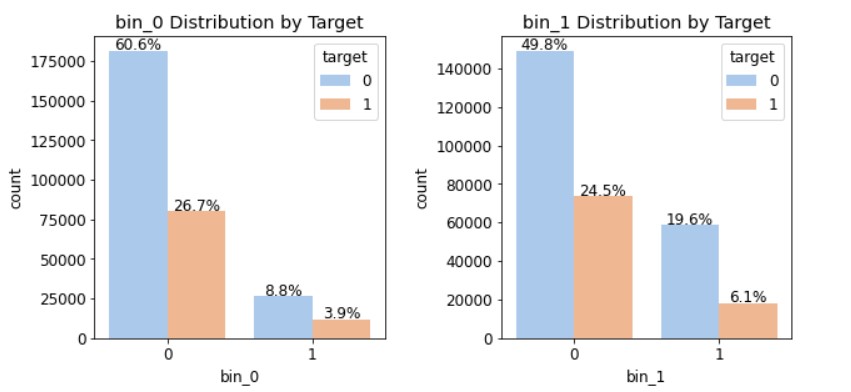
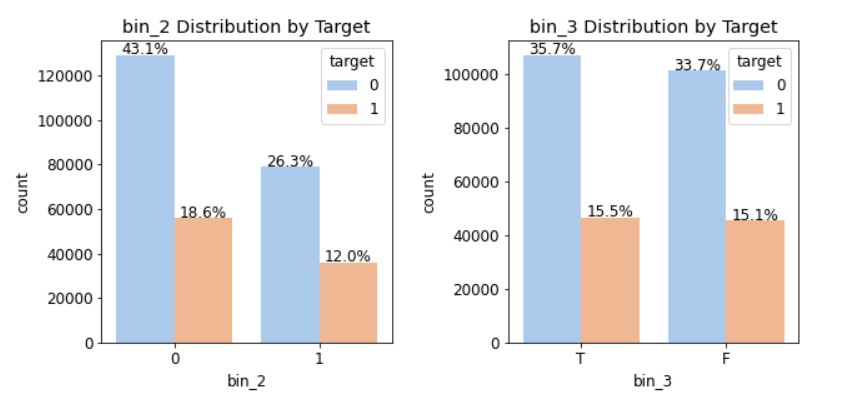

③ 명목형 피처 분포
이번엔 명목형 피처 분포와 명목형 피처별 타깃값 1의 비율을 살펴보자! 이전 글에서 피처 요약표를 만들었을 때 nom_5~9는 고윳값 개수가 많고 의미를 알 수 없는 값이 입력돼 있었기 때문에, 여기서는 nom_0~4까지만 시각화할 것이다.
1단계. 교차분석표 생성 함수 만들기
교차분석표는 범주형 데이터 2개를 비교 분석하는 데 사용되는 표로, 각 범주형 데이터의 빈도나 통계량을 행과 열로 결합해놓은 표를 말한다. 여기서는 교차분석표를 활용해 2개의 범주형 데이터, 즉 명목형 피처와 타깃값을 비교 분석하고, 그 결과를 이용해 그래프를 그릴 것이다.
판다스의 crosstab() 함수로 nom_0과 타깃값(target) 간 교차분석표를 만들어보자.pd.crosstab(train['nom_0'],train['target'])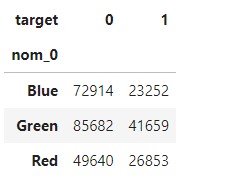
nom_0의 고윳값은 Blue, Green, Red이고 고윳값별 타깃값 0과 1이 몇 개인지 알 수 있다.
비율로 표현하는 게 한눈에 이해하기 쉽기 때문에 normalize 파라미터를 추가해 정규화해보자. normalize 파라미터에 'index'를 전달해서 인덱스를 기준으로 정규화한다. 이를 다시 백분율로 표현하기 위해 100을 곱해야 한다.#정규화 후 비율을 백분율로 표현 crosstab=pd.crosstab(train['nom_0'],train['target'],normalize='index')*100 crosstab
백분율로 잘 정리가 되었다!
이번에는 피처가 열로 설정돼 있어야 그래프를 그리기 편하기 때문에, 인덱스를 재설정해서 피처를 열로 가져오는 작업을 해볼 것이다.crosstab=crosstab.reset_index() #인덱스 재설정 crosstab
교차분석표를 계속 사용할 것이므로 함수로 만들어놓고 다음 단계를 진행하자!def get_crosstab(df,feature): crosstab=pd.crosstab(df[feature],df['target'],normalize='index')*100 crosstab=crosstab.reset_index() return crosstab2단계. 포인트플롯 생성 함수 만들기
앞에서 구한 교차분석표를 사용해서 타깃값 1의 비율을 나타내는 포인트플롯을 그리는 함수를 만들 것이다.
plot_pointplot()은 이미 카운트플롯이 그려진 축에 포인트플롯을 중복으로 그려준다.def plot_pointplot(ax,feature,crosstab): ax2=ax.twinx() #x축은 공유하고 y축은 공유하지 않는 새로운 축 생성 ⓐ #새로운 축에 포인트플롯 그리기 ⓑ ax2=sns.pointplot(x=feature, y=1, data=crosstab, order=crosstab[feature].values, #포인트플롯 순서 color='black', legend=False) #범례 미표시 ax2.set_ylim(crosstab[1].min()-5, crosstab[1].max()*1.1) #y축 범위 설정 ⓒ ax2.set_ylabel('Target 1 Ratio(%)')ⓐ ax.twinx()로 새로운 축 ax2를 만들었다. ax는 카운트플롯을 그리기 위한 축이고, ax2는 포인트플롯을 그리기 위한 축이다. ax와 ax2는 x축을 서로 공유하지만, y축은 서로 다르다.
ⓑ pointplot()의 x 파라미터에는 피처, y 파라미터에는 '타깃값이 1인 비율'을 나타내는 1, data 파라미터에는 교차분석표를 전달했다. order 파라미터에 전달한 것의 의미는 교차분석표의 피처(열) 순서대로 그리겠다는 뜻이다.
ⓒ 포인트플롯을 더 보기 좋게 하기 위해 y축의 범위를 설정했다.3단계. 피처 분포도 및 피처별 타깃값 1의 비율 포인트플롯 생성 함수 만들기
이제 마지막 단계! get_crosstab()과 plot_pointplot() 함수를 활용해 최종 그래프를 그리는 함수를 만들어볼 것이다.
def plot_cat_dist_with_true_ratio(df,features,num_rows,num_cols,size=(15,20)): plt.figure(figsize=size) #전체 Figure 크기 설정 grid=gridspec.GridSpec(num_rows, num_cols) #서브플롯 배치 ⓐ plt.subplots_adjust(wspace=0.45, hspace=0.3) #서브플롯 좌우/상하 여백 설정 for idx, feature in enumerate(features): # ⓑ ax=plt.subplot(grid[idx]) crosstab=get_crosstab(df,feature) #교차분석표 생성 ⓒ #ax축에 타깃값 분포 카운트플롯 그리기 ⓓ sns.countplot(x=feature, data=df, order=crosstab[feature].values, color='skyblue', ax=ax) write_percent(ax,len(df)) #비율 표시 ⓔ plot_pointplot(ax,feature,crosstab) #포인트플롯 그리기 ⓕ ax.set_title(f'{feature} Distribution') #그래프 제목 설정 ⓖ이 함수는 인수로 받는 features 피처마다 타깃값별로 분포도를 그린다. 전체 Figure 크기의 기본값을 (15,20)으로 설정했다.
ⓐ 서브플롯들을 격자 형태로 배치하기 위해 GridSpec을 사용하였다.
ⓑ for문으로 features를 순회하며 서브플롯들을 하나씩 그린다.
ⓒ 각각 서브플롯에 대해 해당 피처와 타깃값의 교차분석표를 만든다.
ⓓ ax축에 카운트플롯을 그린다.
ⓔ 카운트플롯에 비율을 표시한다.
ⓕ 카운트플롯과 같은 축에 포인트플롯을 덧그리고, ⓖ 그래프의 제목을 달았다.nom_features=['nom_0','nom_1','nom_2','nom_3','nom_4'] #명목형 피처 plot_cat_dist_with_true_ratio(train, nom_features,num_rows=3,num_cols=2)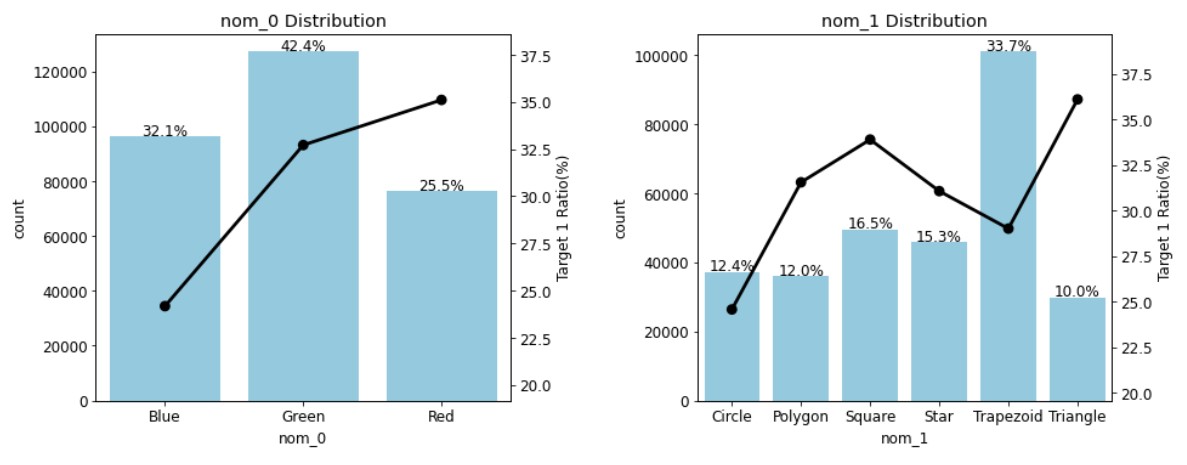

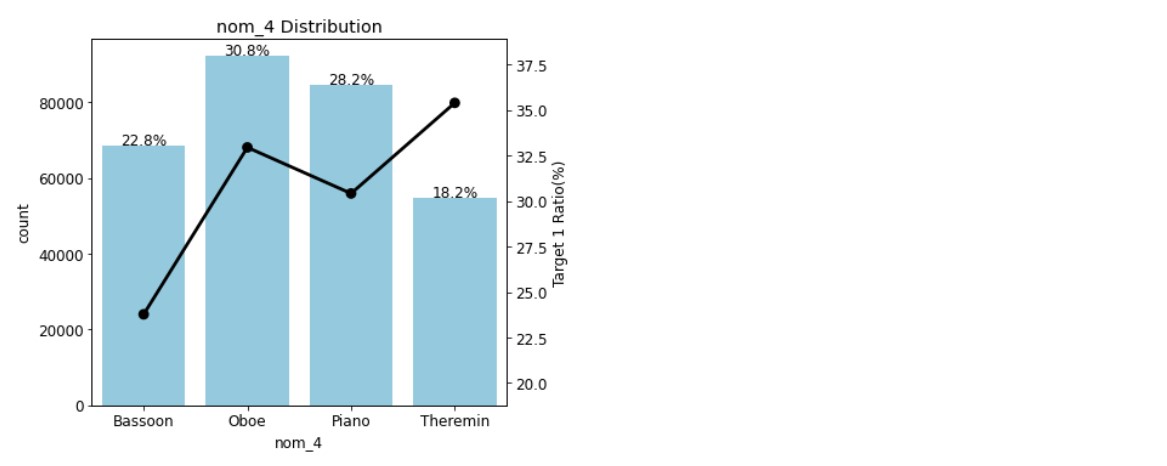
결과 그래프가 잘 나타났다! 이 그림에서 카운트플롯은 피처별 고윳값의 비율을 나타내고, 꺾은 선 그래프는 포인트플롯으로 해당 고윳값 중 타깃값 1의 비율을 나타낸다. 예를 들어 5번째 그래프를 보면, 고윳값 Piano의 비율은 28.2%고 그중 타깃값이 1인 데이터는 30% 정도인 걸 알 수 있다. 자연스럽게 타깃값이 0인 데이터는 70% 정도인 걸 알 수 있다.
이 그래프들을 보면 nom_0~4 피처는 고윳값별로 타깃값 1의 비율이 다른데, 이는 '타깃값에 대한 예측 능력이 있음'을 뜻한다. 따라서 모두 모델링에 사용해야 하는 피처들이다.
또, 명목형 피처는 순서를 무시해도 되고 고윳값 개수도 적기 때문에, 나중에 원-핫 인코딩을 할 것이다.
간단히 원-핫 인코딩의 개념을 복습하자면, 여러 값 중 하나(one)만 활성화(hot)하는 인코딩이다. 레이블 인코딩의 문제를 해결하지만, 피처의 고윳값이 많으면 그만큼 열 개수가 늘어나 모델 훈련 속도가 느려질 우려가 있다.
이럴 때는 비슷한 고윳값끼리 그룹화하거나 다른 인코딩을 적용하는 방법이 있는데, nom_5~9처럼 전체 데이터 양이 별로 많지 않을 때는 열 개수가 늘어나도 모델 훈련 속도에 크게 영향을 주지 않기 때문에 그냥 원-핫 인코딩을 적용하기도 한다.④ 순서형 피처 분포
plot_cat_dist_with_true_ratio() 함수를 사용해 순서형 피처 분포도 살펴보자! 이전 글 '순서형 피처 요약표'에서 확인했듯이 고윳값이 적은 ord_0~3은 2행 2열로, 고윳값이 많은 ord_4~5는 2행 1열로 그래프를 따로 그릴 것이다.
ord_features=['ord_0','ord_1','ord_2','ord_3'] #순서형 피처 plot_cat_dist_with_true_ratio(train, ord_features, num_rows=2, num_cols=2, size=(15,12))

ord_1과 ord_2의 피처 값들의 순서가 정렬되지 않은 걸 볼 수 있다. CategoricalDtype()을 이용해 피처에 순서를 지정하고, 그래프를 다시 그려보자!
- categories: 범주형 데이터 타입으로 인코딩할 값 목록
- ordered: True로 설정하면 categories에 전달한 값의 순서가 유지된다.
from pandas.api.types import CategoricalDtype ord_1_value=['Novice','Contributor','Expert','Master','Grandmaster'] ord_2_value=['Freezing','Cold','Warm','Hot','Boiling Hot','Lava Hot'] #순서를 지정한 범주형 데이터 타입 ord_1_dtype=CategoricalDtype(categories=ord_1_value, ordered=True) ord_2_dtype=CategoricalDtype(categories=ord_2_value, ordered=True) #데이터 타입 변경 train['ord_1']=train['ord_1'].astype(ord_1_dtype) train['ord_2']=train['ord_2'].astype(ord_2_dtype)plot_cat_dist_with_true_ratio(train, ord_features, num_rows=2, num_cols=2, size=(15,12))

순서대로 잘 정렬된 결과 그래프를 보면, 고윳값 순서에 따라 타깃값 1 비율도 비례해서 커진다는 것을 확인할 수 있다.
이번엔 ord_4와 ord_5의 분포를 가로 길이를 늘려 2행 1열로 그려보자.plot_cat_dist_with_true_ratio(train, ['ord_4','ord_5'], num_rows=2, num_cols=1, size=(15,12))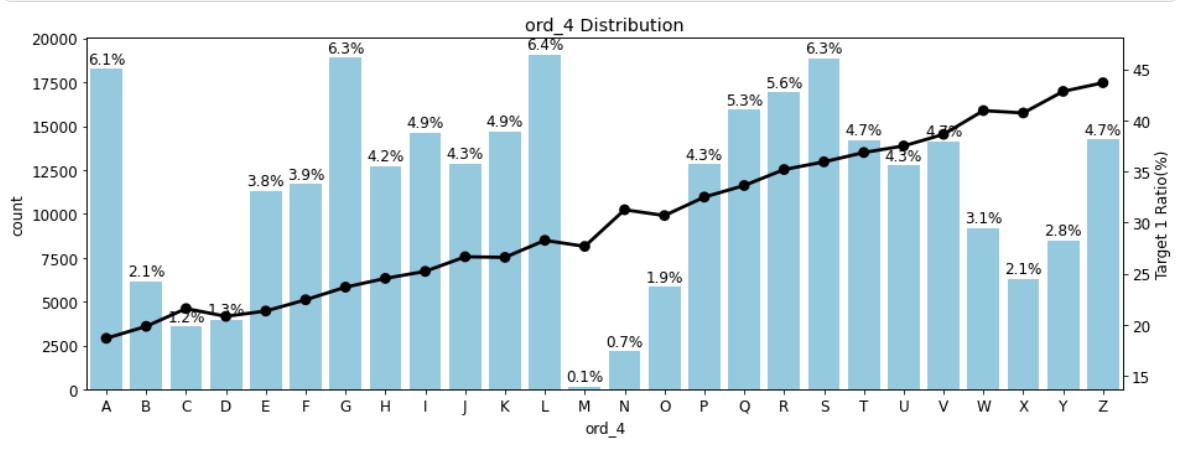

ord_5는 고윳값 개수가 너무 많아 x축 라벨이 겹쳐졌지만, ord_4와 ord_5 둘 다 고윳값 순서에 따라 타깃값 1 비율이 증가한다는 건 알아볼 수 있다.
따라서 순서형 피처 모두 고윳값 순서에 따라 타깃값이 1인 비율이 증가하고, 모든 그래프에서 순서와 비율 사이에 상관관계가 있다는 걸 알 수 있다.⑤ 날짜 피처 분포
마지막으로 날짜(요일과 월) 피처 분포도 살펴보자!
date_features=['day','month'] plot_cat_dist_with_true_ratio(train, date_features, num_rows=2, num_cols=1, size=(10,10))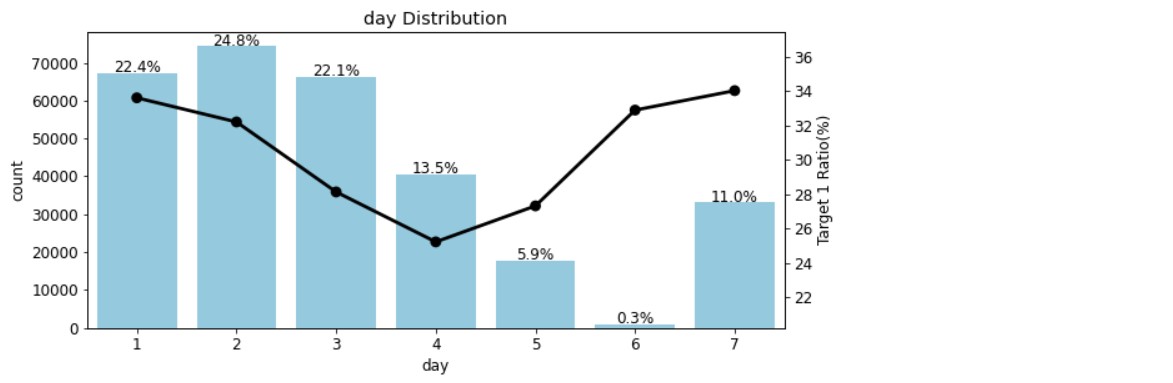

day 피처를 보면 1에서 4로 갈수록 타깃값 1 비율이 줄어들고, 4에서 7로 갈수록 비율이 늘어난다. month 피처는 day 피처와는 반대되는 것을 알 수 있다.
머신러닝 모델은 숫자 값을 가치의 크고 작음으로 해석해서, 12월과 다음해 1월이 한 달 차이지만 1월과 2월의 차이와 같다고 보지 않는다. 이럴 때는 원래 삼각함수 인코딩을 사용하는데, 이 경진대회는 데이터가 그리 크지 않아 명목형 피처와 같이 원-핫 인코딩을 적용할 것이다.분석 정리
- 결측값이 없다.
- 모든 피처가 중요해서 제거할 피처가 없다.
- 이진 피처 인코딩: 값이 숫자가 아닌 이진 피처는 0과 1로 인코딩한다.
- 명목형 피처 인코딩: 전체 데이터가 크지 않기 때문에 원-핫 인코딩을 적용한다.
- 순서형 피처 인코딩: 고윳값들의 순서에 맞게 인코딩한다.
- 날짜 피처 인코딩: 원-핫 인코딩을 적용한다.
'ML.DL' 카테고리의 다른 글
[ML 경진대회] 향후 판매량 예측-베이스라인 모델 (0) 2022.11.27 [ML경진대회] 안전 운전자 예측-성능 개선(2) (0) 2022.11.25 [ML경진대회] 안전 운전자 예측-성능 개선(1) (0) 2022.11.21 [ML경진대회] 범주형 데이터 이진분류-탐색적 데이터 분석(1) (2) 2022.09.30 [머신러닝 딥러닝 문제해결 전략] 문제해결 프로세스 및 체크리스트 (0) 2022.09.12