<musthave 머신러닝딥러닝 문제해결 전략> 8장을 참고해 실습한 내용입니다.
저번 글에서는 '범주형 데이터 이진분류' 경진대회에 참가해서 탐색적 데이터 분석을 하는 글을 블로깅했었는데요.
이번에는 "Porto Seguro's Safe Driver Prediction" 경진대회에 참가해서 탐색적 데이터 분석의 다음 단계를 진행했습니다. 앞 단계에서 선별한 피처들을 제거해 베이스라인 모델을 만들고, 성능 개선을 실습하여 블로깅해 보겠습니다!
1. 베이스라인 모델
베이스라인 모델로 파이썬 래퍼 LightGBM을 사용할 건데요. LightGBM은 마이크로소프트가 개발한 모델로, 빠르면서 성능이 좋아 캐글에서 가장 많이 사용하는 머신러닝 모델입니다.
먼저 훈련, 테스트, 제출 샘플 데이터를 불러오겠습니다.
import pandas as pd
#데이터 경로
data_path='/kaggle/input/porto-seguro-safe-driver-prediction/'
train=pd.read_csv(data_path+'train.csv',index_col='id')
test=pd.read_csv(data_path+'test.csv',index_col='id')
submission=pd.read_csv(data_path+'sample_submission.csv',index_col='id')1.1 피처 엔지니어링
① 데이터 합치기
먼저 훈련 데이터와 테스트 데이터를 합쳐 all_data라는 dataframe을 만듭니다. 뒤에 두 데이터에 동일한 인코딩을 적용하기 위해서인데, 인코딩은 타깃값이 아닌 피처에만 적용해야 하기 때문에 합친 데이터에서 타깃값은 제거하겠습니다.
all_data=pd.concat([train,test], ignore_index=True)
all_data=all_data.drop('target', axis=1) #타깃값 제거그리고 전체 피처 중 원하는 피처만 추출할 때 사용하기 위해, all_data에 있는 모든 피처를 all_features 변수에 저장하겠습니다.
all_features=all_data.columns #전체 피처
all_features
② 명목형 피처 원-핫 인코딩
명목형 데이터에는 고윳값별 순서가 없기 때문에 원-핫 인코딩을 적용하겠습니다. 이름에 'cat'이 포함된 피처가 명목형 피처인데요, 이 피처를 추출한 다음 인코딩해 보겠습니다.
from sklearn.preprocessing import OneHotEncoder
#명목형 피처 추출
cat_features=[feature for feature in all_features if 'cat' in feature]
onehot_encoder=OneHotEncoder() #원-핫 인코더 객체 생성
#인코딩
encoded_cat_matrix=onehot_encoder.fit_transform(all_data[cat_features])
encoded_cat_matrix
인코딩을 하니 184개의 열이 생긴 걸 확인할 수 있습니다.
③ 필요 없는 피처 제거
탐색적 데이터 분석에서 제거할 피처들을 알아봤는데, calc 분류에 속하는 20개의 피처와 그 외 6개 피처들을 제거해야 합니다. 제거할 피처를 제외한 나머지 피처를 remaining_features에 저장하겠습니다.
#추가로 제거할 피처
drop_features=['ps_ind_14','ps_ind_10_bin','ps_ind_11_bin','ps_ind_12_bin','ps_ind_13_bin','ps_car_14']
#'1) 명목형 피처, 2) calc 분류의 피처, 3) 추가 제거할 피처'를 제외한 피처
remaining_features=[feature for feature in all_features
if ('cat' not in feature and
'calc' not in feature and
feature not in drop_features)]필요 없는 피처를 제거했습니다. remaining_features 데이터와 ②에서 인코딩한 encoded_cat_matrix를 합칩니다.
from scipy import sparse
all_data_sprs=sparse.hstack([sparse.csr_matrix(all_data[remaining_features]),
encoded_cat_matrix],
format='csr')여기서 csr_matrix()는 전달받은 데이터를 csr 형식으로 바꿔줍니다.
원-핫 인코딩을 적용하면 희소 행렬(sparse matrix)가 생기는데, 이것이 메모리 낭비를 하는 문제를 개선하는데에 csr 형식으로 표현하는 것이 좋습니다.
④ 데이터 나누기
전체 데이터를 훈련 데이터와 테스트 데이터로 다시 나누고, 타깃값을 y에 할당합니다.
num_train=len(train) #훈련 데이터 개수
#훈련 데이터와 테스트 데이터 나누기
X=all_data_sprs[:num_train]
X_test=all_data_sprs[num_train:]
y=train['target'].values
1.2 평가지표 계산 함수 작성
이 경진대회의 평가지표는 정규화된 지니계수입니다. 그런데 파이썬과 사이킷런에서 기본으로 제공하지 않아서, 사용자 정의 함수를 직접 만들어 정규화 지니계수를 계산하는 함수를 만들어보겠습니다.
넘파이 내장 함수를 이용해 구현해 볼 건데요! 실제 타깃값(y_true)과 예측 확률값(y_pred)을 입력받아 정규화 지니계수를 반환하도록 하겠습니다.
import numpy as np
def eval_gini(y_true, y_pred):
#실젯값과 예측값의 크기가 서로 같은지 확인(값이 다르면 오류 발생)
assert y_true.shape==y_pred.shape
n_samples=y_true.shape[0] #데이터 개수
L_mid=np.linspace(1 / n_samples, 1, n_samples) #대각선 값
#1) 예측값에 대한 지니계수
pred_order=y_true[y_pred.argsort()] #y_pred 크기순으로 y_true 값 정렬
L_pred=np.cumsum(pred_order) / np.sum(pred_order) #로렌츠 곡선: 지니계수는 로렌츠 곡선을 이용해 계산함
G_pred=np.sum(L_mid - L_pred) #예측값에 대한 지니계수
#2) 예측이 완벽할 때 지니계수
true_order=y_true[y_true.argsort()] #y_true 크기순으로 y_true 값 정렬
L_true=np.cumsum(true_order) / np.sum(true_order) #로렌츠 곡선
G_true=np.sum(L_mid - L_true) #예측이 완벽할 때 지니계쑤
#정규화된 지니계수=1) / 2)
return G_pred / G_true정규화 지니계수를 반환하는 함수라는 정도만 이해하고 다음으로 넘어가겠습니다.
이번엔 모델 훈련 시 검증 파라미터에 전달하기 위한 함수입니다.
#LightGBM용 gini() 함수
def gini(preds, dtrain):
labels=dtrain.get_label()
return 'gini', eval_gini(labels, preds), True #반환값
#①평가지표 이름 ②평가 점수 ③평가 점수가 높을수록 좋은지 여부반환값은 ①, ②, ③ 3가지고, 정규화된 지니계수는 값이 클수록 모델 성능이 좋다는 뜻이기 때문에 ③은 True로 고정했습니다.
1.3 모델 훈련 및 성능 검증
이제 데이터와 평가지표 계산 함수가 준비되어서 베이스라인 모델을 훈련시킬 수 있습니다. 훈련 후 예측 결과를 제출해 점수와 등수를 확인해 보겠습니다.
이번 경진대회는 OOF 예측 기법으로 진행해 볼 건데, OOF 예측이란 K 폴드 교차 검증을 수행하면서 각 폴드마다 테스트 데이터로 예측하는 방식입니다. 이 방식은 과대적합에 대응하기 쉽고, 앙상블 효과가 있어 모델 성능이 좋아진다는 장점이 있습니다.
그렇다면 이제 베이스라인 모델을 훈련하면서 OOF 예측을 실제로 해 볼까요?
먼저, StratifiedKFold()로 층화 K 폴드 교차 검증기를 생성합니다. 이 경진대회처럼 타깃값이 불균형할 때는 층화 K 폴드를 수행하는 게 좋습니다.
from sklearn.model_selection import StratifiedKFold
#층화 K 폴드 교차 검증기
folds=StratifiedKFold(n_splits=5, shuffle=True, random_state=1991)5개로 폴드를 나누고, shuffle=True로 전달해 데이터를 섞어줍니다. 일부 폴드에만 특정 패턴 데이터가 몰리는 것을 방지하기 위함입니다.(시계열 데이터일 땐 순서가 중요해서 섞으면 안 됩니다!)
이번엔 LightGBM의 하이퍼파라미터를 설정합니다.
params={'objective': 'binary',
'learning_rate': 0.01,
'force_row_wise': True,
'random_state': 0}이진분류 문제라서 objective는 binary로 설정하고, 학습률은 0.01, 랜덤 시드값은 0으로 설정했습니다. force_row_wise=True는 경고 문구를 없애는 파라미터입니다.
다음으로는 1차원 배열을 2개 만들어 줍니다.
#OOF 방식으로 훈련된 모델로 검증 데이터 타깃값을 예측한 확률을 담을 1차원 배열
oof_val_preds=np.zeros(X.shape[0])
#OOF 방식으로 훈련된 모델로 테스트 데이터 타깃값을 예측한 확률을 담을 1차원 배열
oof_test_preds=np.zeros(X_test.shape[0])oof_val_preds 배열의 크기는 훈련 데이터와 같아야 합니다. 훈련 데이터 개수는 X.shape[0]으로 구합니다.
oof_test_preds 배열의 크기는 테스트 데이터와 같아야 합니다. 테스트 데이터 개수는 X_test.shape[0]으로 구합니다.
둘 다 초기 배열이기 때문에 값을 0으로 채우기 위해, 지정 개수만큼 0으로 채운 배열을 반환하는 np.zeros()를 사용했습니다.
이제 LightGBM 모델을 훈련하는 동시에 OOF 예측도 수행하겠습니다. 아래 코드는 OOF 예측 시 자주 사용하는 패턴이니까 잘 숙지하는 게 좋겠죠?
import lightgbm as lgb
#OOF 방식으로 모델 훈련, 검증, 예측
for idx, (train_idx, valid_idx) in enumerate(folds.split(X,y)): ⓐ
#각 폴드를 구분하는 문구 출력
print('#'*40, f'폴드 {idx+1} / 폴드 {folds.n_splits}', '#'*40)
#훈련용 데이터, 검증용 데이터 설정 ⓑ
X_train, y_train=X[train_idx], y[train_idx] #훈련용 데이터
X_valid, y_valid=X[valid_idx], y[valid_idx] #검증용 데이터
#LightGBM 전용 데이터셋 생성 ⓒ
dtrain=lgb.Dataset(X_train, y_train) #LightGBM 전용 훈련 데이터셋
dvalid=lgb.Dataset(X_valid, y_valid) #LightGBM 전용 검증 데이터셋
#LightGBM 모델 훈련 ⓓ
lgb_model=lgb.train(params=params, #훈련용 하이퍼파라미터
train_set=dtrain, #훈련 데이터셋
num_boost_round=1000, #부스팅 반복 횟수
valid_sets=dvalid, #성능 평가용 검증 데이터셋
feval=gini, #검증용 평가지표
early_stopping_rounds=100, #조기종료 조건
verbose_eval=100) #100번째마다 점수 출력
#테스트 데이터를 활용해 OOF 예측 ⓔ
oof_test_preds += lgb_model.predict(X_test)/folds.n_splits
#모델 성능 평가를 위한 검증 데이터 타깃값 예측 ⓕ
oof_val_preds[valid_idx] += lgb_model.predict(X_valid)
#검증 데이터 예측 확률에 대한 정규화 지니계수 ⓖ
gini_score=eval_gini(y_valid, oof_val_preds[valid_idx])
print(f'폴드 {idx+1} 지니계수: {gini_score}|n')ⓐ에서 folds는 층화 K 폴드 교차 검증기, X는 훈련 데이터의 피처, y는 훈련 데이터의 타깃값입니다. folds.split(X,y)를 호출해 데이터를 K개로 나누고, enumerate()를 적용해 idx와 train_idx, valid_idx를 사용할 수 있게 했습니다.
ⓑ 전체 훈련 데이터를 훈련용과 검증용으로 나누고 ⓒ LightGBM 전용 데이터셋으로 만들어 ⓓ LightGBM 모델을 훈련시킵니다.
ⓔ 훈련된 모델에 테스트 데이터를 주어 타깃 확률값을 예측하는데, 이것이 'OOF 예측 방식'입니다. lightgbm은 predict()를 호출하면 훈련 단계에서 최고 성능을 낸 반복 횟수로 예측하고, 성능은 검증 데이터 평가점수로 판단합니다.
ⓕ는 모델 성능 평가를 위해 검증 데이터를 활용해 예측하는 코드입니다.
ⓖ에서는 현재 폴드에서 '검증 데이터 실제 타깃값'과 '예측 확률값'을 활용해 정규화 지니계수를 계산합니다.
이번엔 이 모델을 훈련할 때 출력된 로그를 보겠습니다. 5개의 로그가 출력되었는데 마지막 폴드에서 출력한 로그만 살펴보겠습니다.
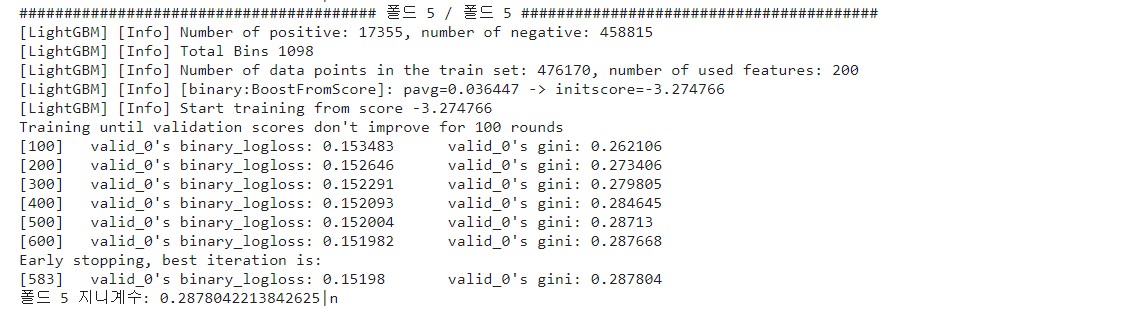
모델 훈련 시 verbose_eval=100으로 설정해서 100번째 이터레이션마다 성능 평가점수를 출력했고, 성능 평가점수는 검증용 데이터로 계산한 값입니다.
그런데 7열부터 보면 성능 평가점수가 logloss와 gini 두 가지가 나온 게 보입니다. logloss(로그 손실)은 이진분류할 때 LightGBM의 기본 평가지표라서 왼쪽에 출력됐고, gini() 함수의 계산값은 오른쪽에 추가로 출력되었습니다.
이터레이션을 반복할수록 지니계수가 커지는데, 13열을 보면 600번 이터레이션까지 출력하고 조기종료되었습니다. 그 아랫줄을 보면 종료 시까지 정규화 지니계수가 가장 높았을 때는 583번째 이터레이션이고, 이때의 지니계수는 0.287804인 것을 확인할 수 있습니다.
드디어 훈련이 끝났네요! 이번엔 검증 데이터로 예측한 확률을 실제 타깃값과 비교해 지니계수를 출력하겠습니다.
print('OOF 검증 데이터 지니계수:', eval_gini(y,oof_val_preds))
8.4 예측 및 결과 제출
최종 예측 확률은 oof_test_preds에 담겨 있습니다. 이 데이터로 제출 파일을 만듭니다.
submission['target']=oof_test_preds
submission.to_csv('submission.csv')이제 커밋하고 제출해 보겠습니다. 코드가 많아 커밋이 10분 정도 걸렸네요...

프라이빗 점수가 0.28424입니다. 성능 개선을 해서 점수를 올려 봅시다!
2. 성능 개선 1: LightGBM 모델
3가지 성능 개선에 도전해 볼 건데, 첫 번째는 베이스라인 모델과 같은 LightBGM을 그대로 사용하되 피처 엔지니어링과 하이퍼파라미터 최적화를 추가로 적용해 보는 것입니다.
먼저 데이터를 불러옵시다.
import pandas as pd
#데이터 경로
data_path='/kaggle/input/porto-seguro-safe-driver-prediction/'
train=pd.read_csv(data_path+'train.csv',index_col='id')
test=pd.read_csv(data_path+'test.csv',index_col='id')
submission=pd.read_csv(data_path+'sample_submission.csv',index_col='id')2.1 피처 엔지니어링
① 데이터 합치기
아까처럼 훈련 데이터와 테스트 데이터를 합치고 타깃값은 제거합니다. 전체 피처도 따로 저장합니다.
all_data=pd.concat([train,test], ignore_index=True)
all_data=all_data.drop('target', axis=1) #타깃값 제거
all_features=all_data.columns #전체 피처② 명목형 피처 원-핫 인코딩
원-핫 인코딩 코드는 베이스라인과 같습니다.
from sklearn.preprocessing import OneHotEncoder
#명목형 피처
cat_features=[feature for feature in all_features if 'cat' in feature]
#원-핫 인코딩 적용
onehot_encoder=OneHotEncoder()
encoded_cat_matrix=onehot_encoder.fit_transform(all_data[cat_features])③ 파생 피처 추가
필요 없는 피처를 추리는 것 외에 할 수 있는 일은 세 가지가 있습니다.
첫 번째, 한 데이터가 가진 결측값 개수를 파생 피처로 만들어 보겠습니다. -1이 결측값이기 때문에 -1의 개수를 구하면 됩니다.
#'데이터 하나당 결측값 개수'를 파생 피처로 추가
all_data['num_missing']=(all_data==-1).sum(axis=1)결측값 개수를 num_missing이라는 피처명으로 all_data에 추가했습니다.
remaining_features는 명목형 피처와 calc 분류의 피처를 제외한 나머지 피처명으로 정의하겠습니다. 그리고 방금 생성한 파생 피처 num_missing도 remaining_features에 추가하겠습니다.
#명목형 피처,calc 분류의 피처를 제외한 피처
remaining_features=[feature for feature in all_features
if ('cat' not in feature and 'calc' not in feature)]
#num_missing을 remaining_features에 추가
remaining_features.append('num_missing')
두 번째는, 모든 ind 피처 값을 연결해서 새로운 피처를 만들려고 합니다. ind 피처가 총 18개이니 18개 값이 연결될 것입니다. 18개 값을 연결한 새로운 피처를 만들고, 이 피처명을 'mix_ind'라고 하겠습니다.
먼저 분류가 ind인 피처들을 추출하고 이 피처들을 순회하면서 모든 값을 연결하면 됩니다.
#분류가 ind인 피처
ind_features=[feature for feature in all_features if 'ind' in feature]
is_first_feature=True
for ind_feature in ind_features:
if is_first_feature:
all_data['mix_ind']=all_data[ind_feature].astype(str)+'_'
is_first_feature=False
else:
all_data['mix_ind']+=all_data[ind_feature].astype(str)+'_'새로운 피처 mix_ind에 어떤 값이 만들어졌는지 볼까요?
all_data['mix_ind']
모든 값이 '_'로 잘 연결되었네요.
세 번째로는, 명목형 피처의 고윳값별 개수를 새로운 피처로 추가하겠습니다. 고윳값별 개수는 value_counts()로 구합니다. 예를 들어, ps_ind_04_cat 피처의 고윳값별 개수는 아래 코드로 확인할 수 있습니다.
all_data['ps_ind_04_cat'].value_counts()
ps_ind_04_cat 피처는 고윳값 0을 866,864개, 1을 620,936개 갖는다는 의미입니다.
value_counts()는 Series 타입을 반환하는데, 이것을 딕셔너리 타입으로 바꾸려면 to_dict()를 호출합니다.
all_data['ps_ind_04_cat'].value_counts().to_dict()
이 코드를 활용해 명목형 피처의 고윳값별 개수를 파생 피처로 만들어 보겠습니다. cat 분류에 속하는 피처들(cat_features)과 mix_ind 피처를 모두 명목형 피처로 간주하겠습니다.
cat_count_features=[]
for feature in cat_features+['mix_ind']:
val_counts_dict=all_data[feature].value_counts().to_dict()
all_data[f'{feature}_count']=all_data[feature].apply(lambda x:
val_counts_dict[x])
cat_count_features.append(f'{feature}_count')cat_count_features에 방금 추가한 새로운 피처명이 들어 있습니다.
cat_count_features
기존 명목형 피처명 뒤에 '_count'가 붙었습니다.
④ 필요 없는 피처 제거
탐색적 데이터 분석에서 필요 없다고 판단한 피처는 제거하고, 지금까지 피처 엔지니어링한 모든 데이터를 합치겠습니다.
from scipy import sparse
#필요 없는 피처들
drop_features=['ps_ind_14','ps_ind_10_bin','ps_ind_11_bin','ps_ind_12_bin','ps_ind_13_bin','ps_car_14']
#remaining_features, cat_count_features에서 drop_features를 제거한 데이터
all_data_remaining=all_data[remaining_features+cat_count_features].drop(drop_features,axis=1)
#데이터 합치기
all_data_sprs=sparse.hstack([sparse.csr_matrix(all_data_remaining),
encoded_cat_matrix],
format='csr')
⑤ 데이터 나누기
피처 엔지니어링을 다 했으니 다시 훈련 데이터와 테스트 데이터로 나눕니다.
num_train=len(train) #훈련 데이터 개수
#훈련 데이터와 테스트 데이터 나누기
X=all_data_sprs[:num_train]
X_test=all_data_sprs[num_train:]
y=train['target'].values다음은 원래 정규화 지니계수 계산 함수를 정의할 순서인데, 두 함수 모두 베이스라인과 완전히 같아서 생략하겠습니다.
2.2 하이퍼파라미터 최적화
성능이 우수한 모델을 만들려면 이 과정이 꼭 필요합니다. 이번에는 베이지안 최적화 기법을 활용해 하이퍼파라미터를 조정해 보겠습니다.
① 데이터셋 준비
import lightgbm as lgb
from sklearn.model_selection import train_test_split
#8:2 비율로 훈련 데이터, 검증 데이터 분리(베이지안 최적화 수행용)
X_train, X_valid, y_train, y_valid=train_test_split(X,y,
test_size=0.2,
random_state=0)
#베이지안 최적화용 데이터셋
bayes_dtrain=lgb.Dataset(X_train, y_train)
bayes_dvalid=lgb.Dataset(X_valid, y_valid)train_test_split()은 전체 데이터를 훈련 데이터와 테스트 데이터로 나누는 함수입니다. test_size=0.2를 전달하여 전체 중 80%를 훈련 데이터로, 나머지 20%를 검증 데이터로 나눴습니다. 그리고 나뉜 데이터를 활용해 베이지안 최적화용 데이터셋을 만들었습니다.
② 하이퍼파라미터 범위 설정
하이퍼파라미터 범위를 설정하는 방법은 두 가지가 있는데, 저는 다른 상위권 캐글러가 설정한 하이퍼파라미터를 참고하는 방법으로 범위를 설정해 보겠습니다. param_bounds에 탐색할 하이퍼파라미터 범위를 지정하고, 값을 고정할 하이퍼파라미터는 fixed_params에 저장했습니다.
#베이지안 최적화를 위한 하이퍼파라미터 범위
param_bounds={'num_leaves': (30,40),
'lambda_l1': (0.7,0.9),
'lambda_l2': (0.9,1),
'feature_fraction':(0.6,0.7),
'bagging_fraction':(0.6,0.9),
'min_child_samples':(6,10),
'min_child_weight':(10,40)}
#값이 고정된 하이퍼파라미터
fixed_params={'objective': 'binary',
'learing_rate': 0.005,
'bagging_freq':1,
'force_row_wise': True,
'random_state':1991}
③ (베이지안 최적화용) 평가지표 계산 함수 작성
아래의 eval_function()은 베이지안 최적화를 수행하기 위한 평가지표(지니계수) 계산 함수입니다. 최적화하려는 LightGBM 모델의 하이퍼파라미터 7개를 인수로 받고 지니계수를 반환합니다.
def eval_function(num_leaves, lambda_l1, lambda_l2, feature_fraction, bagging_fraction, min_child_samples,
min_child_weight):
'''최적화하려는 평가지표(지니계수) 계산 함수'''
#베이지안 최적화를 수행할 하이퍼파라미터 ⓐ
params={'num_leaves': int(round(num_leaves)),
'lambda_l1': lambda_l1,
'lambda_l2': lambda_l2,
'feature_fraction': feature_fraction,
'bagging_fraction': bagging_fraction,
'min_child_samples': int(round(min_child_samples)),
'min_child_weight': min_child_weight,
'features_pre_filter': False}
#고정된 하이퍼파라미터도 추가 ⓑ
params.update(fixed_params)
print('하이퍼파라미터:', params)
#LightGBM 모델 훈련 ⓒ
lgb_model=lgb.train(params=params,
train_set=bayes_dtrain,
num_boost_round=2500,
valid_sets=bayes_dvalid,
feval=gini,
early_stopping_rounds=300,
verbose_eval=False)
#검증 데이터로 예측 수행 ⓓ
preds=lgb_model.predict(X_valid)
#지니계수 계산 ⓔ
gini_score=eval_gini(y_valid,preds)
print(f'지니계수: {gini_score}|n')
return gini_score ⓕⓐ 먼저 최적화할 하이퍼파라미터를 정의합니다. num_leaves와 min_child_samples는 정수여야 하는데, 베이지안 최적화를 수행하면 eval_function()에 인수들이 모두 실수형이 됩니다. 그래서 int(round(num_leaves))로 실수형을 다시 정수형으로 바꿔 주었습니다.
ⓑ 고정 하이퍼파라미터를 추가했고, params는 딕셔너리 타입이기 때문에 update() 함수로 원소를 추가했습니다.
ⓒ LightGBM 모델을 훈련하고 ⓓ 검증 데이터로 예측을 수행하고 ⓔ 지니계수를 계산하고 ⓕ 최종적으로 지니계수를 반환합니다.
④ 최적화 수행
이제 베이지안 최적화 객체를 생성하겠습니다. 생성 파라미터로 eval_fuction과 param_bounds를 전달합니다.
from bayes_opt import BayesianOptimization
#베이지안 최적화 객체 생성
optimizer=BayesianOptimization(f=eval_function, #평가지표 계산함수
pbounds=param_bounds, #하이퍼파라미터 범위
random_state=0)다음으로 maximize() 메서드를 호출해 베이지안 최적화를 수행합니다.
#베이지안 최적화 수행
optimizer.maximize(init_points=3, n_iter=6)init_points는 무작위로 하이퍼파라미터를 탐색하는 횟수고, n_iter는 베이지안 최적화 반복 횟수입니다. 베이지안 최적화는 init_points와 n_iter를 더한 값만큼 반복합니다. 그래서 위 코드를 실행하면 모델 훈련을 총 9번 반복하면서 베이지안 최적화가 진행되는데, 30분이나 걸렸네요.
⑤ 결과 확인
최적화가 끝났으니, 최적 하이퍼파라미터를 출력해 봅시다.
#평가함수 점수가 최대일 때 하이퍼파라미터
max_params=optimizer.max['params']
max_params
그런데 이중 num_leaves와 min_child_samples는 원래 정수형 하이퍼파라미터이므로 정수형으로 변환해서 다시 저장하겠습니다.
#정수형 하이퍼파라미터 변환
max_params['num_leaves']=int(round(max_params['num_leaves']))
max_params['min_child_samples']=int(round(max_params['min_child_samples']))그리고 값이 고정된 하이퍼파라미터도 추가하겠습니다.
#값이 고정된 하이퍼파라미터 추가
max_params.update(fixed_params)진짜 최종으로 최적 하이퍼파라미터를 출력해 보겠습니다!
max_params
2.3 모델 훈련 및 성능 검증
베이지안 최적화는 최적 예측기(최적 하이퍼파라미터 값들로 훈련된 모델)을 제공하지 않기 때문에, 베이지안 최적화로 찾은 하이퍼파라미터를 활용해 LightGBM 모델을 다시 훈련해 볼 겁니다. 모델 훈련 코드는 베이스라인과 비슷한데, LightGBM 훈련 시 사용한 파라미터를 max_params로 바꾸고, 부스팅 반복 횟수를 2500번, 조기종료 조건을 300으로 바꿨습니다.
from sklearn.model_selection import StratifiedKFold
#층화 K 폴드 교차 검증기 생성
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=1991)
#OOF 방식으로 훈련된 모델로 검증 데이터 타깃값을 예측한 확률을 담을 1차원 배열
oof_val_preds = np.zeros(X.shape[0])
#OOF 방식으로 훈련된 모델로 테스트 데이터 타깃값을 예측한 확률을 담을 1차원 배열
oof_test_preds = np.zeros(X_test.shape[0])
#OOF 방식으로 모델 훈련, 검증, 예측
for idx, (train_idx, valid_idx) in enumerate(folds.split(X, y)):
print('#' * 40, f'폴드 {idx+1} / 폴드 {folds.n_splits}', '#' * 40)
#훈련용 데이터, 검증용 데이터 설정
X_train, y_train = X[train_idx], y[train_idx]
X_valid, y_valid = X[valid_idx], y[valid_idx]
#LightGBM 전용 데이터셋 생성
dtrain = lgb.Dataset(X_train, y_train)
dvalid = lgb.Dataset(X_valid, y_valid)
lgb_model = lgb.train(params=max_params, #최적 하이퍼파라미터**
train_set=dtrain, #훈련 데이터셋
num_boost_round=2500, #부스팅 반복 횟수**
valid_sets=dvalid, #성능 평가용 검증 데이터셋
feval=gini, #검증용 평가지표
early_stopping_rounds=300, #조기종료 조건**
verbose_eval=100) #100번째마다 점수 출력
#테스트 데이터를 활용해 OOF 예측
oof_test_preds += lgb_model.predict(X_test)/folds.n_splits
#모델 성능 평가를 위한 검증 데이터 타깃값 예측
oof_val_preds[valid_idx] += lgb_model.predict(X_valid)
#검증 데이터 예측 확률에 대한 정규화 지니계수
gini_score = eval_gini(y_valid, oof_val_preds[valid_idx])
print(f'폴드 {idx+1} 지니계수 : {gini_score}\n')이번엔 20분이 걸렸네요. 그러면 마지막 폴드의 출력 로그만 살펴보겠습니다.
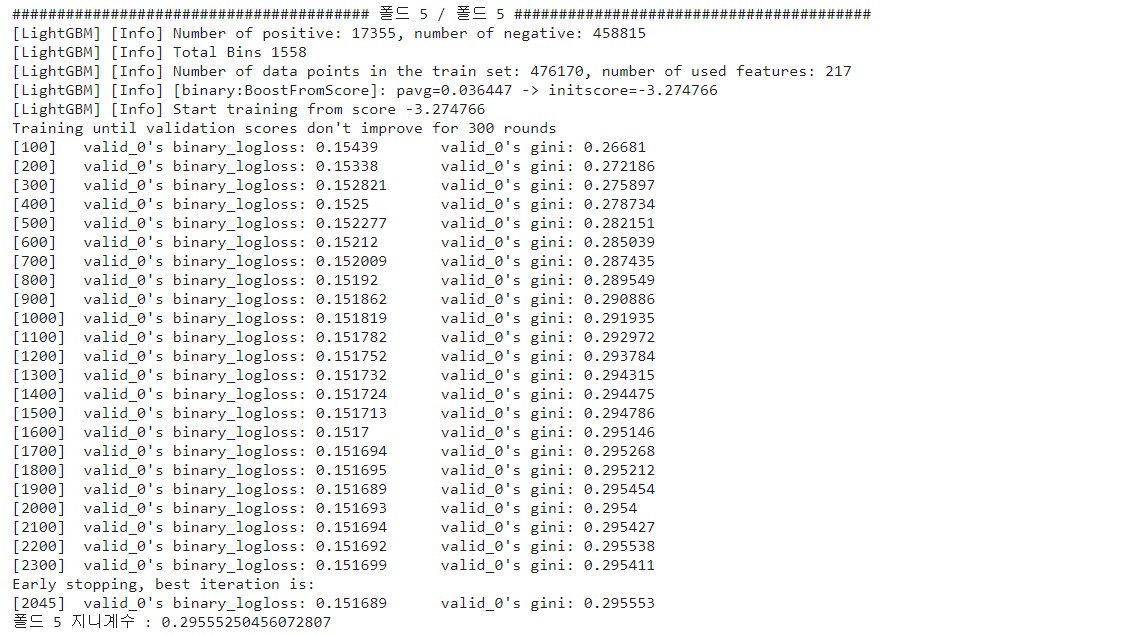
2,300번 만에 조기종료했고, 마지막 폴드 기준 최고 지니계수는 0.295553입니다. 베이스라인 모델보다 0.007749 정도 높아졌는데, 성능이 좋아진 것을 확인할 수 있습니다.
검증 데이터로 예측한 확률과 실제 타깃값의 지니계수를 출력해 보겠습니다.
print('OOF 검증 데이터 지니계수 : ', eval_gini(y, oof_val_preds))
베이스라인보다 0.0085 정도 높아졌습니다.
2.4 예측 및 결과 제출
최종 예측 확률인 oof_test_preds를 활용해 제출 파일을 만들고, 커밋 후 제출해 보겠습니다.
이번 글에서는 <안전 운전자 예측> 경진대회의 베이스라인 모델을 만들고, 성능 개선 3가지 중 1번째인 LightGBM 모델까지 해서 점수를 올려 보았습니다.
다음 글에서는 XGBoost로 모델을 바꾸고, 그 두 개를 앙상블해서 점수를 더 올려 보는 실습을 블로깅하겠습니다.
'ML.DL' 카테고리의 다른 글
| [ML 경진대회] 향후 판매량 예측-베이스라인 모델 (0) | 2022.11.27 |
|---|---|
| [ML경진대회] 안전 운전자 예측-성능 개선(2) (0) | 2022.11.25 |
| [ML경진대회] 범주형 데이터 이진분류-탐색적 데이터 분석(2) (0) | 2022.10.02 |
| [ML경진대회] 범주형 데이터 이진분류-탐색적 데이터 분석(1) (2) | 2022.09.30 |
| [머신러닝 딥러닝 문제해결 전략] 문제해결 프로세스 및 체크리스트 (0) | 2022.09.12 |



댓글