-
[텍스트마이닝] 단어연관 및 word networkPython 2023. 2. 10. 15:00
동아대 INSPIRE - python텍스트마이닝 26강을 실습 및 정리한 내용입니다.
지난 글에서는 한글 단어들의 빈도 분석을 실습했었는데요! 이번에는 단어들의 상관관계를 파악해 보고, 단어들간의 연관을 network 그림으로 그려 보겠습니다.
1. 패키지 및 데이터 불러오기
먼저 필요한 패키지들을 불러옵니다.
import numpy as np from sklearn.feature_extraction.text import CountVectorizer from matplotlib import font_manager import matplotlib.pyplot as plt import networkx as nx import pickle저장되어 있는 파일을 불러옵니다. 연관 분석을 할 때는 단어들이 하나의 문장처럼 쭉 나열된, 즉 조인된 형태의 자료가 필요합니다.
with open('ko_stopped_join.bin', 'rb') as fp: ko_word = pickle.load(fp)파일이 저장된 ko_word를 실행해 보면 이렇게 저장되어 있는 것을 확인할 수 있습니다.

2. DTM 자료 만들기
DTM 자료를 만들기 위해서는 CountVectorizer로 빈도를 계산하고, fit_transform 명령어를 사용합니다. 가장 많이 언급된 단어 50개를 가져오겠습니다. todense()는 묶여진 형태를 풀어 줄 때 사용합니다.
ko_countVectorizer = CountVectorizer(max_features=50) ko_dtm = ko_countVectorizer.fit_transform(ko_word) ko_dtm_dense = ko_dtm.todense() print(ko_dtm_dense)세로 118개, 가로 50개인 DTM 자료가 행렬 형태로 만들어졌습니다.

ko_dtm_dense.shape
그리고 단어들의 이름을 words_name에 저장합니다.
words_name = ko_countVectorizer.get_feature_names()3. 단어간 상관관계 구하기
이번엔 corrcoef 를 사용해서 상관관계를 살펴보겠습니다.
ko_word_corr = np.corrcoef(ko_dtm_dense, rowvar=0)ko_word_corr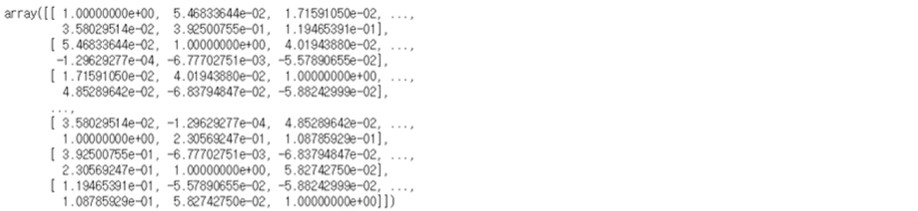
상관계수가 구해졌지만 깔끔하지 않네요. 행렬 형태를 데이터프레임 형태로 바꿔 볼까요?
import pandas as pd pd.DataFrame(ko_word_corr)
자기 자신끼리의 상관계수는 1이고, 나머지 단어들과의 상관계수가 쭉 잘 나열된 것이 보입니다.
그럼 이제는 이 형태를 단어의 이름까지 넣어서 만드는 작업을 해 보겠습니다.
ko_word_edges = []어떤 단어들이 연결되는지 for문으로 작성해 줍니다. append를 사용해 단어의 이름도 추가합니다.
for i in range(ko_dtm_dense.shape[1]): for j in range (ko_dtm_dense.shape[1]): ko_word_edges.append((words_name[i], words_name[j], ko_word_corr[i,j]))여기서 ko_dtm_dense.shape[1]을 하면 dtm 자료의 가로, 즉 단어의 개수인 50을 가져옵니다. 따라서 50x50의 상관관계를 만든다는 것을 뜻합니다.
ko_dtm_dense.shape[1]
아까처럼 상관관계 표를 데이터프레임 형태로 나타내 보면, 단어의 이름까지 나오는 것을 볼 수 있습니다.
pd.DataFrame(ko_word_edges)
4. 단어X단어 행렬 만들기
tdm과 dtm 자료를 연산하면 ttm 형태가 됩니다.
ko_ttm=np.dot(ko_dtm_dense.T, ko_dtm_dense)50x50의 ttm 자료가 행렬 형태로 만들어졌습니다.
print(ko_ttm.shape)
print(ko_ttm)
5. word network 시각화
이제 word network로 시각화해 보겠습니다. 단어의 이름이 한글이기 때문에, 폰트 경로를 윈도우 폰트로 설정해 주는 것 잊지 않으셨죠?
ko_font_location = "C:/Windows/Fonts/malgun.ttf" ko_font_name = font_manager.FontProperties(fname=ko_font_location).get_name() plt.rc('font', family=words_name)위에서 만든 TTM 자료에서 10x10만 가져오고, word network를 설정해 줍니다.
g = nx.Graph(ko_ttm[:10, :10]) en_map = dict(zip(g.nodes(), words_name)) nx.draw(g, labels=en_map, with_labels=True, font_family=ko_font_name) plt.show()10개 단어들의 연관이 word network로 출력되었습니다! 상위 단어들이기 때문에 서로 연관이 많다는 것이 보이네요.
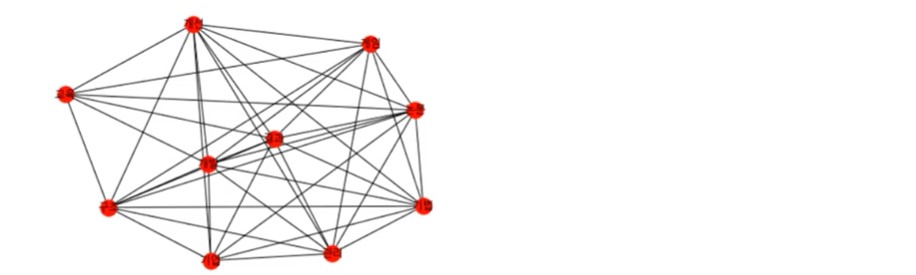
이렇게 한글 단어의 연관 분석도 배워 보았습니다. 이렇게 나타내면 어떤 단어들이 더 관계가 있는지 파악해 볼 수 있다는 것을 알 수 있었습니다.
'Python' 카테고리의 다른 글
[텍스트마이닝] 한글 Document cluster (0) 2023.02.16 [텍스트마이닝] 한글 빈도분석과 WordCloud (0) 2023.01.27 [텍스트마이닝] LDA 결과의 시각화 (0) 2023.01.16 [텍스트마이닝] Text Clustering 개념 및 활용 (0) 2023.01.04 [텍스트마이닝] 단어 연관 분석과 Word Network (0) 2022.12.28