-
[텍스트마이닝] 단어 연관 분석과 Word NetworkPython 2022. 12. 28. 23:11
동아대 INSPIRE - python 텍스트마이닝 12강을 정리, 실습한 내용입니다.
1. TF와 TF-IDF
왼쪽에 문서, 위쪽에 단어가 있는 형태를 Document Term Matrix, 즉 DTM이라고 하고, 반대로 되어 있는 경우는 TDM이라고 한다.
DTM은 문서 간의 관계나 문서 간의 근접성을 파악하는 데이터로서 D-Clusting, 빈도-클라우드, 상관관계 파악을 하는데에 적합하고 TDM은 단어를 기준으로 클러스팅하는 데에 적합하다.
DTM과 TDM을 곱하면 TTM(단어와 단어 간의 관계)를 나타낼 수 있다. 이 형태는 많은 메모리를 필요로 하기 때문에 edge list(단어-단어-빈도)로 변환해 분석한다.
model system algorithm data clinic mobile 문서 1 24 21 9 0 0 3 문서 2 32 10 5 0 3 0 문서 3 12 16 5 0 0 0 문서 4 6 7 2 0 0 0 문서 5 43 31 20 0 30 0 문서 6 2 0 0 18 7 16 문서 7 0 0 1 32 12 0 문서 8 3 0 0 22 4 2 문서 9 1 0 0 34 27 25 문서 10 6 0 0 17 4 2 위 표처럼 하나의 문서에서 각 단어가 몇 번씩 나왔는지 빈도로 나열한 것을 TF(Term Frequency)라고 한다. TF는 상대적인 가중치가 반영이 덜 됐기 때문에 빈도가 많이 나타나는 단어에 쏠리는 현상이 있다. 글의 특성이나 주제에 따라 많이 등장할 수밖에 없는 단어들이 있는데 그 단어들이 다른 단어들에 비해 빈도가 너무 높아서 결과가 편향되는 문제가 있다.
model system algorithm data clinic mobile 문서 1 2.5 14.6 4.6 0 0 2.1 문서 2 3.4 6.9 2.6 0 1.1 0 문서 3 1.3 11.1 2.6 0 0 0 문서 4 0.6 4.9 1.0 0 0 0 문서 5 4.5 21.5 10.2 0 1.1 0 문서 6 ... ... ... ... ... ... 문서 7 ... ... ... ... ... ... 문서 8 ... ... ... ... ... ... 문서 9 ... ... ... ... ... ... 문서 10 ... ... ... ... ... ... 이런 문제를 보완하기 위해 등장한 것이 단어마다 가중치를 둔 TF-IDF(Term Frequency-Inverse Document Frequency)이다.

기본 TF에 log(전체 문서 수/그 단어가 문서에서 나타난 수)를 곱한 값으로, 점수가 높은 단어일수록 다른 문서에는 많지 않고 해당 특정한 문서에서 자주 등장하는 단어이다. 단어 기준으로 문서의 유사성을 파악하는데 수월하다.
예로 몇 가지 계산해 보자. 문서 1에서 model의 TF-IDF 값은 24에 log(10/9)를 곱한 2.5이다. 그런데 algorithm의 TF-IDF 값은 9에 log(10/5)를 곱한 4.6으로, model보다 TF 값은 훨씬 적은데 TF-IDF 값은 더 크게 나왔다. 그 이유는 특정한 문서에서 자주 등장했기 때문에 많은 가중치를 얻게 된 것이고 뻔한 단어들은 적은 가중치 적용했기 때문이다.
따라서, 문서 간의 유사성을 통해 하위 주제와 하위 내용을 찾을 때는 TF-IDF를 많이 사용한다.
2. 단어 연관 분석
01. 패키지 및 데이터 불러오기
import pandas as pd import numpy as np from nltk.tokenize import word_tokenize from nltk.corpus import stopwords from nltk.stem import PorterStemmer import re from sklearn.feature_extraction.text import CountVectorizer #DTM을 쉽게 만들어 줌 import matplotlib.pyplot as pltdata=pd.read_csv('wos_al_.csv', encoding='euc-kr').ABSTRACT02. 데이터 전처리
doc_set = [] #문서들이 들어옴 words = [] #단어들이 들어옴 words_joined = [] #단어들을 조인함 for doc in data: if type(doc) != float: doc_set.append(doc.replace("_", " ")) stopWords = set(stopwords.words("english")) #nltk에 있는 불용어 사전을 stopWords에 할당 stemmer = PortersStemmer() #어간추출 for doc in data: noPunctionWords = re.sub(r"[^a-zA-Z]+", " ", str(doc)) #영어 빼고 다 지움 tokenizedwords = word_tokenize(noPunctionWords.lower()) stoppedwords = [w for w in tokenizedwords if w not in stopWords] stemmedwords = [stemmer.stem(w) for w in stoppedwords] words_joined.append(' '.join(stemmedwords)) #조인 words.append(stemmedwords) #조인하지 않고 appendcountVectorizer = CountVectorizer(max_features=50) #많이 언급된 단어 50개만 뽑음 dtm = countVectorizer.fit_transform(words_joined) #조인된 형태로 빈도를 계산해 dtm을 만듦 dtm_dense = dtm.todense() #행렬의 형태로 만듦 print(tdm_dense)
dtm_name = countVectorizer.get_feature_names() #dtm 이름을 각 값에 넣기 위해서 dtm_nameword_corr=np.corrcoef(dtm_dense, rowvar=dtm_name) #상관계수(-1에서 1 사이 값을 가짐) D=pd.DataFrame(word_corr) #데이터프레임 형태로 바꿈 D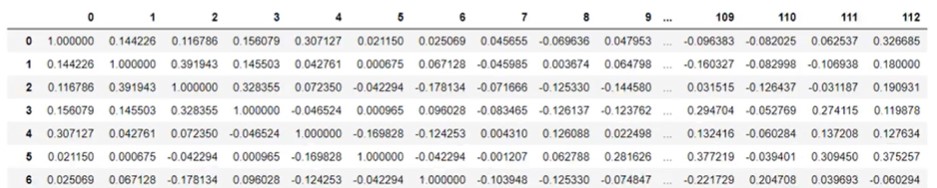
word_edges = [] for i in range(dtm_dense.shape[1]): #dtm_dense에 dtm_name을 붙임 for j in range (dtm_dense.shape[1]): word_edges.append((dtm_name[i], dtm_name[j], word_corr[i,j])) word_edges_sorted = sorted(word_edges, key=lambda x:x[2], reverse=True) #결과를 높은 순으로 print(word_edges_sorted) #단어와 단어 간의 상관 출력
A=pd.DataFrame(word_edges_sorted) A

2. Word Network
import networkx as nx #네트워크 분석 패키지 edgelist=np.dot(dtm_dense.T, dtm_dense) #전치 dtm_dense와 dtm_dense로 edgelist를 만듦 edgelist
ngraph = nx.Graph(edgelist[:, :]) ngraph_map = dict(zip(ngraph.nodes(), dtm_name)) #노드와 dtm_name을 연결 ngraph_map
nx.draw(ngraph, labels=ngraph_map, with_labels=True) plt.show()
'Python' 카테고리의 다른 글
[텍스트마이닝] 한글 Document cluster (0) 2023.02.16 [텍스트마이닝] 단어연관 및 word network (2) 2023.02.10 [텍스트마이닝] 한글 빈도분석과 WordCloud (0) 2023.01.27 [텍스트마이닝] LDA 결과의 시각화 (0) 2023.01.16 [텍스트마이닝] Text Clustering 개념 및 활용 (0) 2023.01.04