-
[ML 경진대회] 향후 판매량 예측-성능 개선ML.DL 2022. 11. 28. 13:42
<Musthave 머신러닝딥러닝 문제해결 전략> 9장을 실습한 내용입니다.
이전 글에서 베이스라인 모델을 생성했으니, 이제 베이스라인 모델의 성능을 개선해 보겠습니다.
2. 성능 개선
베이스라인 모델은 똑같이 LightGBM입니다. 이번 경진대회에서는 피처 엔지니어링할 요소가 많은데, 총 6단계를 진행합니다.
먼저 데이터를 불러오겠습니다.
import numpy as np import pandas as pd import warnings warnings.filterwarnings(action='ignore') #경고 메시지 생략 #데이터 경로 data_path = '/kaggle/input/competitive-data-science-predict-future-sales/' sales_train = pd.read_csv(data_path + 'sales_train.csv') shops = pd.read_csv(data_path + 'shops.csv') items = pd.read_csv(data_path + 'items.csv') item_categories = pd.read_csv(data_path + 'item_categories.csv') test = pd.read_csv(data_path + 'test.csv') submission = pd.read_csv(data_path + 'sample_submission.csv')2.1 피처 엔지니어링 1: 피처명 한글화와 데이터 다운캐스팅
베이스라인과 똑같이 피처명을 한글화합니다.
sales_train = sales_train.rename(columns={'date': '날짜', 'date_block_num': '월ID', 'shop_id': '상점ID', 'item_id': '상품ID', 'item_price': '판매가', 'item_cnt_day': '판매량'}) shops = shops.rename(columns={'shop_name': '상점명', 'shop_id': '상점ID'}) items = items.rename(columns={'item_name': '상품명', 'item_id': '상품ID', 'item_category_id': '상품분류ID'}) item_categories = item_categories.rename(columns= {'item_category_name': '상품분류명', 'item_category_id': '상품분류ID'}) test = test.rename(columns={'shop_id': '상점ID', 'item_id': '상품ID'})데이터 다운캐스팅도 베이스라인과 똑같이 진행합니다.
def downcast(df, verbose=True): start_mem = df.memory_usage().sum() / 1024**2 for col in df.columns: dtype_name = df[col].dtype.name if dtype_name == 'object': pass elif dtype_name == 'bool': df[col] = df[col].astype('int8') elif dtype_name.startswith('int') or (df[col].round() == df[col]).all(): df[col] = pd.to_numeric(df[col], downcast='integer') else: df[col] = pd.to_numeric(df[col], downcast='float') end_mem = df.memory_usage().sum() / 1024**2 if verbose: print('{:.1f}% 압축됨'.format(100 * (start_mem - end_mem) / start_mem)) return df all_df = [sales_train, shops, items, item_categories, test] for df in all_df: df = downcast(df)
2.2 피처 엔지니어링 2: 개별 데이터 피처 엔지니어링
이번에는 sales_train, shops, items, item_categories 데이터를 '각각' 피처 엔지니어링하겠습니다.
① sales_train 이상치 제거 및 전처리
sales_train의 피처 중 판매가와 판매량 피처의 이상치를 제거하겠습니다. 판매가, 판매량이 음수라면 환불 건이거나 오류이기 때문에 이상치로 간주하겠습니다. 또 판매가가 50,000 이상인 데이터, 판매량 1,000 이상인 데이터도 이상치로 간주하겠습니다. 따라서 판매가가 0~50,000 사이이고, 판매량이 0~1,000 사이인 데이터만 추출하겠습니다.
#판매가가 0보다 큰 데이터 추출 sales_train = sales_train[sales_train['판매가'] > 0] #판매가가 50,000보다 작은 데이터 추출 sales_train = sales_train[sales_train['판매가'] < 50000] #판매량이 0보다 큰 데이터 추출 sales_train = sales_train[sales_train['판매량'] > 0] #판매량이 1,000보다 작은 데이터 추출 sales_train = sales_train[sales_train['판매량'] < 1000]이번에는 데이터 전처리를 해 보겠습니다. 상점명을 조금 다르게 기입해서 같은 상점인데 따로 기록돼 있는 상점이 네 쌍 있습니다.
print(shops['상점명'][0], '||', shops['상점명'][57]) print(shops['상점명'][1], '||', shops['상점명'][58]) print(shops['상점명'][10], '||', shops['상점명'][11]) print(shops['상점명'][39], '||', shops['상점명'][40])
차이가 나는 부분을 노란색으로 표시했더니 확실히 거의 같아 보입니다.
따라서 sales_train과 test 데이터에서 상품ID 0은 57로, 1은 58로, 10은 11로, 39는 40으로 수정하겠습니다.
#sales_train 데이터에서 상점ID 수정 sales_train.loc[sales_train['상점ID'] == 0, '상점ID'] = 57 sales_train.loc[sales_train['상점ID'] == 1, '상점ID'] = 58 sales_train.loc[sales_train['상점ID'] == 10, '상점ID'] = 11 sales_train.loc[sales_train['상점ID'] == 39, '상점ID'] = 40 #test 데이터에서 상점ID 수정 test.loc[test['상점ID'] == 0, '상점ID'] = 57 test.loc[test['상점ID'] == 1, '상점ID'] = 58 test.loc[test['상점ID'] == 10, '상점ID'] = 11 test.loc[test['상점ID'] == 39, '상점ID'] = 40② shops 파생 피처 생성 및 인코딩
shops에도 상점명이 러시아로 기록돼 있습니다. 다른 캐글러가 상점명의 첫 단어가 도시라는 사실을 알아내서, 상점명을 활용해 도시 피처를 만들 수 있습니다. 상점명 피처를 공백 기준으로 나눈 뒤, 첫번째 단어를 가져오면 됩니다.
shops['도시'] = shops['상점명'].apply(lambda x: x.split()[0])도시 피처가 잘 만들어졌는지 확인해 볼까요?
shops['도시'].unique()
잘 만들어진 것 같은데, 맨 처음 도시명 앞에 느낌표가 있네요. 특수 문자가 잘못 기재된 것이니 제거하겠습니다.
shops.loc[shops['도시'] =='!Якутск', '도시'] = 'Якутск'도시명은 범주형 피처인데 머신러닝 모델은 문자를 인식하지 못하므로 숫자로 바꾸기 위해 인코딩을 적용하겠습니다.
from sklearn.preprocessing import LabelEncoder #레이블 인코더 생성 label_encoder = LabelEncoder() #도시 피처 레이블 인코딩 shops['도시'] = label_encoder.fit_transform(shops['도시'])이제 상점명 피처는 모델링에 필요가 없기 때문에 제거하겠습니다. 같은 의미가 상점ID 피처에 내포돼 있기 때문입니다.
#상점명 피처 제거 shops = shops.drop('상점명', axis=1) shops.head()
최종적으로 shops에는 상점ID와 도시 피처가 남았고, 각 상점이 어느 도시에 위치하는지를 나타냅니다.
③ items 파생 피처 생성
이번에는 items를 활용해 '첫 판매월' 피처를 구해 보겠습니다. 우선 상품명 피처는 상품ID와 일대일 매칭되어 있어서 제거하겠습니다.
#상품명 피처 제거 items = items.drop(['상품명'], axis=1)다음으로 상품이 맨 처음 팔린 월을 피처로 만들겠습니다. sales_train(판매 내역 데이터)을 상품ID 기준으로 그룹화한 뒤, 그룹에서 월ID 최솟값을 구하면 됩니다. 상품ID가 가장 처음 등장한 날의 월ID를 구하는 겁니다. groupby()와 집계 함수 min을 사용해서 구하겠습니다.
#상품이 맨 처음 팔린 날을 피처로 추가 items['첫 판매월'] = sales_train.groupby('상품ID').agg({'월ID': 'min'})['월ID'] items.head()
첫 판매월 피처가 잘 추가되었습니다. 결측값이 있는지 확인해 보겠습니다.
items[items['첫 판매월'].isna()]
결측값이 368개나 있네요. 이 결측값은 해당 상품이 한 번도 판매된 적이 없다는 뜻입니다.
훈련 데이터의 월ID는 0부터 33이고, 테스트 데이터의 월ID는 34입니다. 월ID 33까지 한 번도 팔리지 않은 상품이 있다면 그 상품이 처음 팔린 달을 34로 가정해도 됩니다. 따라서 첫 판매월 피처의 결측값을 34로 대체하겠습니다.
#첫 판매월 피처의 결측값을 34로 대체 items['첫 판매월'] = items['첫 판매월'].fillna(34)④ item_categories 파생 피처 생성 및 인코딩
이번엔 item_categories에서 '대분류'라는 파생 피처를 만들고 인코딩해보겠습니다. 상품분류명 피처는 또 러시아어인데, 상품분류명의 첫 단어가 범주 대분류라는 점을 다른 캐글러가 찾아냈습니다.
아까 상점명에서 도시명을 추출한 코드와 같은 방식으로 상품분류명에서 대분류 피처를 추출해 보겠습니다.
#상품분류명의 첫 단어를 대분류로 추출 item_categories['대분류'] = item_categories['상품분류명'].apply(lambda x: x.split()[0])대분류 피처의 고윳값 개수를 출력해 보겠습니다.
item_categories['대분류'].value_counts()
여기서 고윳값이 5개 미만인 대분류는 모두 'etc'로 바꾸겠습니다. 대분류 하나가 범주를 일정 개수 이상을 갖는 게 성능 향상에 유리합니다.
def make_etc(x): if len(item_categories[item_categories['대분류']==x]) >= 5: return x else: return 'etc' # 대분류의 고윳값 개수가 5개 미만이면 'etc'로 바꾸기 item_categories['대분류'] = item_categories['대분류'].apply(make_etc)잘 처리됐는지 확인해 보겠습니다.
item_categories.head()
이제 범주형 피처인 대분류를 인코딩하고, 상품분류명 피처는 더 이상 필요 없으므로 제거하겠습니다.
#레이블 인코더 생성 label_encoder = LabelEncoder() #대분류 피처 레이블 인코딩 item_categories['대분류'] = label_encoder.fit_transform(item_categories['대분류']) #상품분류명 피처 제거 item_categories = item_categories.drop('상품분류명', axis=1)2.3 피처 엔지니어링 3: 데이터 조합 및 파생 피처 생성
이번에도 먼저 데이터 조합을 생성하고 월간 판매량, 평균 판매가, 판매건수 피처를 만들겠습니다.
① 데이터 조합
베이스라인과 같은 방식으로 월ID, 상점ID, 상품ID 조합을 생성합니다.
from itertools import product train = [] #월ID, 상점ID, 상품ID 조합 생성 for i in sales_train['월ID'].unique(): all_shop = sales_train.loc[sales_train['월ID']==i, '상점ID'].unique() all_item = sales_train.loc[sales_train['월ID']==i, '상품ID'].unique() train.append(np.array(list(product([i], all_shop, all_item)))) idx_features = ['월ID', '상점ID', '상품ID'] #기준 피처 train = pd.DataFrame(np.vstack(train), columns=idx_features)② 파생 피처 생성
이번에는 3개의 피처를 만들 건데, 먼저 월ID, 상점ID, 상품ID별 '월간 판매량'과 '평균 판매가' 피처를 만듭니다.
group = sales_train.groupby(idx_features).agg({'판매량': 'sum', '판매가': 'mean'}) group = group.reset_index() group = group.rename(columns={'판매량': '월간 판매량', '판매가': '평균 판매가'}) train = train.merge(group, on=idx_features, how='left') train.head()
새로운 파생 피처는 잘 추가됐는데 결측값이 있네요. 이건 나중에 0으로 대체하고, 지금은 임시로 만든 변수인 group을 가비지 컬렉션해 주겠습니다.
import gc #group 변수 가비지 컬렉션 del group gc.collect();세 번째 파생 피처는 '기준 피처별 상품 판매건수'입니다. 집계 함수로 count를 써서 구할 수 있습니다.
#상품 판매건수 피처 추가 group = sales_train.groupby(idx_features).agg({'판매량': 'count'}) group = group.reset_index() group = group.rename(columns={'판매량': '판매건수'}) train = train.merge(group, on=idx_features, how='left') #가비지 컬렉션 del group, sales_train gc.collect() train.head()
3개의 파생 피처를 추가했습니다. 판매건수의 결측값도 나중에 0으로 대체하겠습니다.
2.4 피처 엔지니어링 4: 데이터 합치기
① 테스트 데이터 이어붙이기
train에 테스트 데이터를 이어붙이는 코드는 베이스라인과 같습니다.
#테스트 데이터 월ID를 34로 설정 test['월ID'] = 34 #train과 test 이어붙이기 all_data = pd.concat([train, test.drop('ID', axis=1)], ignore_index=True, keys=idx_features) #결측값을 0으로 대체 all_data = all_data.fillna(0) all_data.head()
② 모든 데이터 병합
all_data에 모든 데이터를 병합하고 다운캐스팅해 주겠습니다.
#나머지 데이터 병합 all_data = all_data.merge(shops, on='상점ID', how='left') all_data = all_data.merge(items, on='상품ID', how='left') all_data = all_data.merge(item_categories, on='상품분류ID', how='left') #데이터 다운캐스팅 all_data = downcast(all_data)
병합된 데이터는 이제 필요 없으니 가비지 컬렉션을 해 주겠습니다.
#가비지 컬렉션 del shops, items, item_categories gc.collect();2.5 피처 엔지니어링 5: 시차 피처 생성
이번에는 시차 피처를 만들 건데, 시차 피처는 과거 시점에 관한 피처로 성능 향상에 도움이 돼서 시계열 문제에서 자주 만드는 파생 피처입니다. 이 경진대회에서 만들 시차 피처는 '월간 평균 판매량'을 기준으로 하겠습니다.
① 기준 피처별 월간 평균 판매량 파생 피처 생성
기준 피처로 그룹화해 '월간' 평균 판매량을 구해주는 함수를 만들 것이기 때문에, 기준 피처의 첫 번째 요소는 '월ID'여야 합니다. 그리고 과도하게 세분화되지 않도록 기준 피처의 개수는 2개나 3개로 설정하겠습니다.
def add_mean_features(df, mean_features, idx_features): #기준 피처 확인: 첫 번째 요소와 개수 확인 assert (idx_features[0] == '월ID') and \ len(idx_features) in [2, 3] #파생 피처명 설정: 기준 피처 개수가 2개일 때, 3개일 때 나눠서 설정 if len(idx_features) == 2: feature_name = idx_features[1] + '별 평균 판매량' else: feature_name = idx_features[1] + ' ' + idx_features[2] + '별 평균 판매량' #기준 피처를 토대로 그룹화해 월간 평균 판매량(feature_name) 구하기 group = df.groupby(idx_features).agg({'월간 판매량': 'mean'}) group = group.reset_index() group = group.rename(columns={'월간 판매량': feature_name}) #df와 group 병합: 원본 데이터 df를 기준으로 df = df.merge(group, on=idx_features, how='left') #데이터 다운캐스팅: False는 문구 출력하지 않음 df = downcast(df, verbose=False) #새로 만든 feature_name 피처명을 mean_features 리스트에 추가 mean_features.append(feature_name) #가비지 컬렉션 del group gc.collect() return df, mean_features방금 만든 add_mean_features() 함수를 이용해, ['월ID', '상품ID']로 그룹화한 월간 평균 판매량과 ['월ID', '상품ID', '도시']로 그룹화한 월간 평균 판매량을 만들겠습니다.
#그룹화 기준 피처 중 '상품ID'가 포함된 파생 피처명을 담을 리스트 item_mean_features = [] #['월ID', '상품ID']로 그룹화한 월간 평균 판매량 파생 피처 생성 all_data, item_mean_features = add_mean_features(df=all_data, mean_features=item_mean_features, idx_features=['월ID', '상품ID']) #['월ID', '상품ID', '도시']로 그룹화한 월간 평균 판매량 파생 피처 생성 all_data, item_mean_features = add_mean_features(df=all_data, mean_features=item_mean_features, idx_features=['월ID', '상품ID', '도시'])잘 추가됐는지 확인해 볼까요?
item_mean_features
이번에는 ['월ID', '상점ID', '상품분류ID']를 기준 피처로 그룹화해 월간 평균 판매량을 구해 보겠습니다.
#그룹화 기준 피처 중 '상점ID'가 포함된 파생 피처명을 담을 리스트 shop_mean_features = [] #['월ID', '상점ID', '상품분류ID']로 그룹화한 월간 평균 판매량 파생 피처 생성 all_data, shop_mean_features = add_mean_features(df=all_data, mean_features=shop_mean_features, idx_features=['월ID', '상점ID', '상품분류ID'])
② 시차 피처 생성 원리 및 함수 구현
지금까지 3개의 기준 피처별 월간 평균 판매량 피처를 만들었습니다. 이를 활용해 시차 피처를 구해 보겠습니다. 시차 피처는 원하는 시점까지 생성할 수 있는데 너무 과거면 예측력이 오히려 떨어지므로 세 달 전까지만 만들겠습니다.
시차 피처를 추가하는 함수인 add_lag_feature() 함수를 만들겠습니다.
def add_lag_features(df, lag_features_to_clip, idx_features, lag_feature, nlags=3, clip=False): #시차 피처 생성에 필요한 DataFrame 부분(기준 피처와 시차 적용 피처)만 복사 df_temp = df[idx_features + [lag_feature]].copy() #시차 피처 생성: nlags 인수 3만큼 for i in range(1, nlags+1): #시차 피처명 lag_feature_name = lag_feature +'_시차' + str(i) #df_temp 열 이름 설정 df_temp.columns = idx_features + [lag_feature_name] #df_temp의 date_block_num 피처에 1 더하기: 월을 한 달씩 미뤄야 한 달 전 시차 피처를 만들 수 있음 df_temp['월ID'] += 1 #idx_feature를 기준으로 df와 df_temp 병합하기: 중복 행은 제거 df = df.merge(df_temp.drop_duplicates(), on=idx_features, how='left') #결측값 0으로 대체 df[lag_feature_name] = df[lag_feature_name].fillna(0) #0~20 사이로 제한할 시차 피처명을 lag_features_to_clip에 추가 if clip: lag_features_to_clip.append(lag_feature_name) #데이터 다운캐스팅 df = downcast(df, False) #가비지 컬렉션 del df_temp gc.collect() return df, lag_features_to_clip이제 이 함수를 이용해 시차 피처 몇 가지를 만들어 보겠습니다.
시차 피처 생성 1: 월간 판매량
기준 피처는 '월ID', '상점ID', '상품ID'로 해서 월간 판매량의 세 달치 시차 피처를 만들겠습니다. clip=True를 전달해 타깃값은 0~20 사이로 제한하겠습니다.
lag_features_to_clip = [] #0~20 사이로 제한할 시차 피처명을 담을 리스트 idx_features = ['월ID', '상점ID', '상품ID'] #기준 피처 #idx_features를 기준으로 월간 판매량의 세 달치 시차 피처 생성 all_data, lag_features_to_clip = add_lag_features(df=all_data, lag_features_to_clip=lag_features_to_clip, idx_features=idx_features, lag_feature='월간 판매량', nlags=3, clip=True) #값을 0~20 사이로 제한all_data.head().T
nlags=3이므로 월간 판매량_시차1, 월간 판매량_시차2, 월간 판매량_시차3 피처로 총 3개가 잘 만들어졌습니다.
새로 만든 세 피처의 이름은 lag_features_to_clip에 저장돼 있습니다.
lag_features_to_clip
시차 피처 생성 2: 판매건수, 평균 판매가
판매건수와 평균 판매가는 타깃값이 아니라서 clip 파라미터는 생략했습니다.
#idx_features를 기준으로 판매건수 피처의 세 달치 시차 피처 생성 all_data, lag_features_to_clip = add_lag_features(df=all_data, lag_features_to_clip=lag_features_to_clip, idx_features=idx_features, lag_feature='판매건수', nlags=3) #idx_features를 기준으로 평균 판매가 피처의 세 달치 시차 피처 생성 all_data, lag_features_to_clip = add_lag_features(df=all_data, lag_features_to_clip=lag_features_to_clip, idx_features=idx_features, lag_feature='평균 판매가', nlags=3)시차 피처 생성 3: 평균 판매량
item_mean_features에 저장된 '상품ID별 평균 판매량'과 '상품ID 도시별 평균 판매량' 피처값에 대해서 시차 피처를 만들겠습니다. '월ID', '상점ID', '상품ID' 기준으로 '상품ID별 평균 판매량'과 '상품ID 도시별 평균 판매량'의 시차 피처를 만드는 코드입니다.
#idx_features를 기준으로 item_mean_features 요소별 시차 피처 생성 for item_mean_feature in item_mean_features: all_data, lag_features_to_clip = add_lag_features(df=all_data, lag_features_to_clip=lag_features_to_clip, idx_features=idx_features, lag_feature=item_mean_feature, nlags=3, clip=True) #값을 0~20 사이로 제한 #item_mean_features 피처 제거: 모델링에 사용하지 않음 all_data = all_data.drop(item_mean_features, axis=1)다음으로 shop_mean_features에 저장된 '상점 상품분류ID별 평균 판매량' 피처를 활용해 시차 피처를 구해 보겠습니다. 기준 피처는 '월ID', '상점ID', '상품분류ID'로 하겠습니다.
#['월ID', '상점ID', '상품분류ID']를 기준으로 shop_mean_features 요소별 시차 피처 생성 for shop_mean_feature in shop_mean_features: all_data, lag_features_to_clip = add_lag_features(df=all_data, lag_features_to_clip=lag_features_to_clip, idx_features=['월ID', '상점ID', '상품분류ID'], lag_feature=shop_mean_feature, nlags=3, clip=True) #shop_mean_features 피처 제거: 모델링에 사용하지 않음 all_data = all_data.drop(shop_mean_features, axis=1)시차 피처 생성 마무리: 결측값 처리
시차 피처를 세 달 치까지 만들어서 월ID가 0, 1, 2인 데이터에는 결측값이 생깁니다. 결측값을 없애려면 월ID가 3 미만인 데이터를 제거해야 합니다.
#월ID 3미만인 데이터 제거 all_data = all_data.drop(all_data[all_data['월ID'] < 3].index)2.6 피처 엔지니어링 6: 기타 피처 엔지니어링
이제 간단한 피처 5가지를 추가하고, 필요 없는 피처는 제거하겠습니다.
① 기타 피처 추가
⑴ 월간 판매량 시차 피처들의 평균
all_data['월간 판매량 시차평균'] = all_data[['월간 판매량_시차1', '월간 판매량_시차2', '월간 판매량_시차3']].mean(axis=1)이 피처도 판매량과 관련되어 있으니 clip()을 사용해 값을 0~20 사이로 조정하겠습니다.
#0~20 사이로 값 제한 all_data[lag_features_to_clip + ['월간 판매량', '월간 판매량 시차평균']] = \ all_data[lag_features_to_clip + ['월간 판매량', '월간 판매량 시차평균']].clip(0, 20)⑵ 시차 변화량
이번에는 나누기 연산으로 시차 변화량 피처 두 가지를 만들겠습니다.
all_data['시차변화량1'] = all_data['월간 판매량_시차1']/all_data['월간 판매량_시차2'] all_data['시차변화량1'] = all_data['시차변화량1'].replace([np.inf, -np.inf], np.nan).fillna(0) all_data['시차변화량2'] = all_data['월간 판매량_시차2']/all_data['월간 판매량_시차3'] all_data['시차변화량2'] = all_data['시차변화량2'].replace([np.inf, -np.inf], np.nan).fillna(0)코드에서 replace([np.inf, -np.inf], np.nan).fillna(0) 부분은 값을 0으로 나누는 상황을 대처하는 방어 코드입니다.
⑶ 신상 여부
첫 판매월이 현재 월과 같다면 신상품이겠죠? 첫 판매월과 월ID가 같으면 True, 다르면 False를 신상여부 피처에 추가했습니다.
all_data['신상여부'] = all_data['첫 판매월'] == all_data['월ID']⑷ 첫 판매 후 경과 기간
현재 월에서 첫 판매월을 빼면 첫 판매 후 기간이 얼마나 지났는지 구할 수 있습니다.
all_data['첫 판매 후 기간'] = all_data['월ID'] - all_data['첫 판매월']⑸ 월(month)
월ID 피처를 12로 나눈 나머지는 월과 같습니다.
all_data['월'] = all_data['월ID'] % 12② 필요 없는 피처 제거
지금까지 만든 피처 중 첫 판매월, 평균 판매가, 판매건수는 다른 파생 피처를 만드는 데 쓰였기 때문에 모델링에 필요가 없으므로 제거하겠습니다. 이어서 다운캐스팅도 해주겠습니다.
#첫 판매월, 평균 판매가, 판매건수 피처 제거 all_data = all_data.drop(['첫 판매월', '평균 판매가', '판매건수'], axis=1)all_data = downcast(all_data, False) #데이터 다운캐스팅2.7 피처 엔지니어링 7: 마무리
드디어 피처 엔지니어링이 모두 끝났습니다! info() 함수를 사용해 all_data에 어떤 피처가 있는지 살펴볼까요?
all_data.info()
총 31개 열 중 '월간 판매량'은 타깃값이고 나머지 30개는 피처입니다.
이제 all_data를 훈련, 검증, 테스트 데이터로 나누고, 가비지 컬렉션을 해 주겠습니다.
#훈련 데이터 (피처) X_train = all_data[all_data['월ID'] < 33] X_train = X_train.drop(['월간 판매량'], axis=1) #검증 데이터 (피처) X_valid = all_data[all_data['월ID'] == 33] X_valid = X_valid.drop(['월간 판매량'], axis=1) #테스트 데이터 (피처) X_test = all_data[all_data['월ID'] == 34] X_test = X_test.drop(['월간 판매량'], axis=1) #훈련 데이터 (타깃값) y_train = all_data[all_data['월ID'] < 33]['월간 판매량'] #검증 데이터 (타깃값) y_valid = all_data[all_data['월ID'] == 33]['월간 판매량'] #가비지 컬렉션 del all_data gc.collect();2.8 모델 훈련 및 성능 검증
이제 데이터로 모델을 훈련해 보겠습니다. 조기 종료 조건은 150번으로 설정했고, 범주형 데이터에는 상점ID와 상품분류ID 외에도 시, 대분류, 월을 추가했습니다.
import lightgbm as lgb #LightGBM 하이퍼파라미터 params = {'metric': 'rmse', 'num_leaves': 255, 'learning_rate': 0.005, 'feature_fraction': 0.75, 'bagging_fraction': 0.75, 'bagging_freq': 5, 'force_col_wise': True, 'random_state': 10} cat_features = ['상점ID', '도시', '상품분류ID', '대분류', '월'] ** #LightGBM 훈련 및 검증 데이터셋 dtrain = lgb.Dataset(X_train, y_train) dvalid = lgb.Dataset(X_valid, y_valid) #LightGBM 모델 훈련 lgb_model = lgb.train(params=params, train_set=dtrain, num_boost_round=1500, valid_sets=(dtrain, dvalid), early_stopping_rounds=150, ** categorical_feature=cat_features, verbose_eval=100)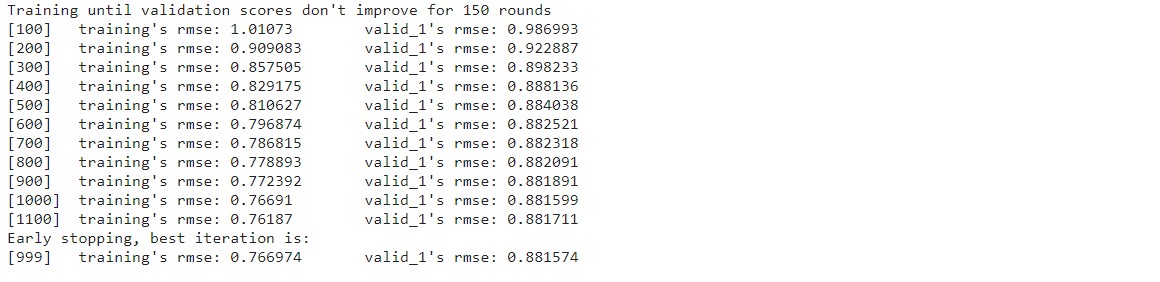
1100번째 이터레이션까지 결과를 출력하고 조기종료했습니다. 종료 시까지 성능이 가장 우수했을 때는 999번째 이터레이션이었고, 이때 검증 데이터의 RMSE 값은 0.881574입니다. RMSE 값은 낮을수록 좋은데, 책보다 훨씬 낮은 값이 나왔네요! 베이스라인 모델에서는 1.00722였으니 0.125646만큼 낮아졌습니다.
2.9 예측 및 결과 제출
훈련된 모델을 활용해 최종 예측하고 결과 파일을 만듭니다.
#예측 preds = lgb_model.predict(X_test).clip(0, 20) #제출 파일 생성 submission['item_cnt_month'] = preds submission.to_csv('submission.csv', index=False)가비지 컬렉션도 해 주겠습니다.
del X_train, y_train, X_valid, y_valid, X_test, lgb_model, dtrain, dvalid gc.collect();커밋하고 제출해 보겠습니다!

제출 결과 퍼블릭 점수는 0.89293입니다. 베이스라인 모델보다 0.19241만큼 좋아졌습니다!
이렇게 이 책의 머신러닝 경진대회 실습이 끝났습니다. 캐글러의 코드를 그대로 참고하는 수준이었지만, 여러 번 반복하며 실습하니 코드 이해도 되고 경진대회 프로세스가 잘 이해가 되는 좋은 경험이었습니다.
이제 다음 글부터는 딥러닝 경진대회를 다루는 글을 블로깅하겠습니다!
'ML.DL' 카테고리의 다른 글
[DL 경진대회] 항공 사진 내 선인장 식별(2) (0) 2023.01.30 [DL 경진대회] 항공 사진 내 선인장 식별(1) (2) 2023.01.30 [ML 경진대회] 향후 판매량 예측-베이스라인 모델 (0) 2022.11.27 [ML경진대회] 안전 운전자 예측-성능 개선(2) (0) 2022.11.25 [ML경진대회] 안전 운전자 예측-성능 개선(1) (0) 2022.11.21